2.2.Displaying & Describing Data
Measures of central tendency and spread
2025-09-17
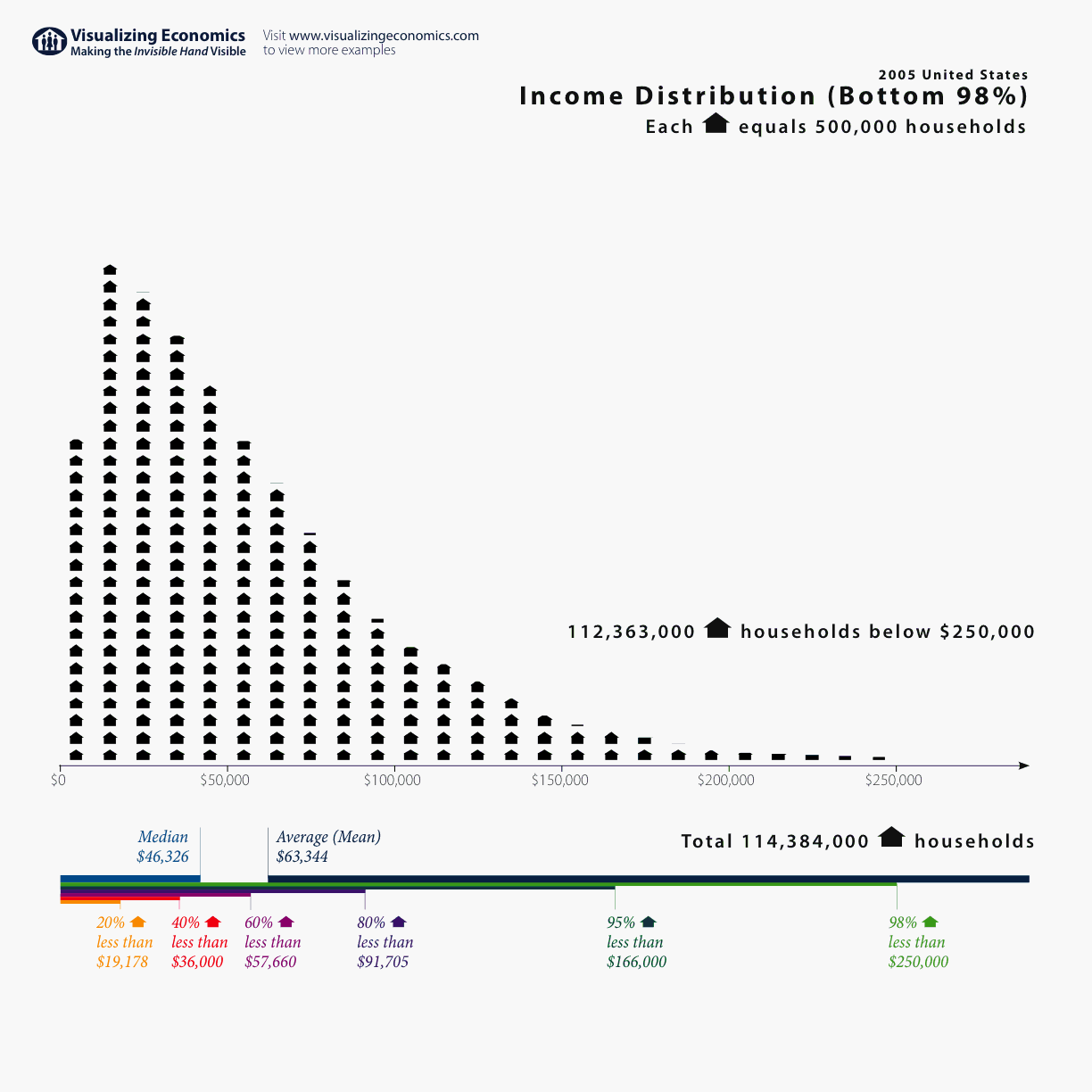
Case Study
2005 U.S. Census. The plot shows the income per household distribution for the bottom 98% of the population. Median = \(\sim46\)k; Mean: \(\sim63\)k.
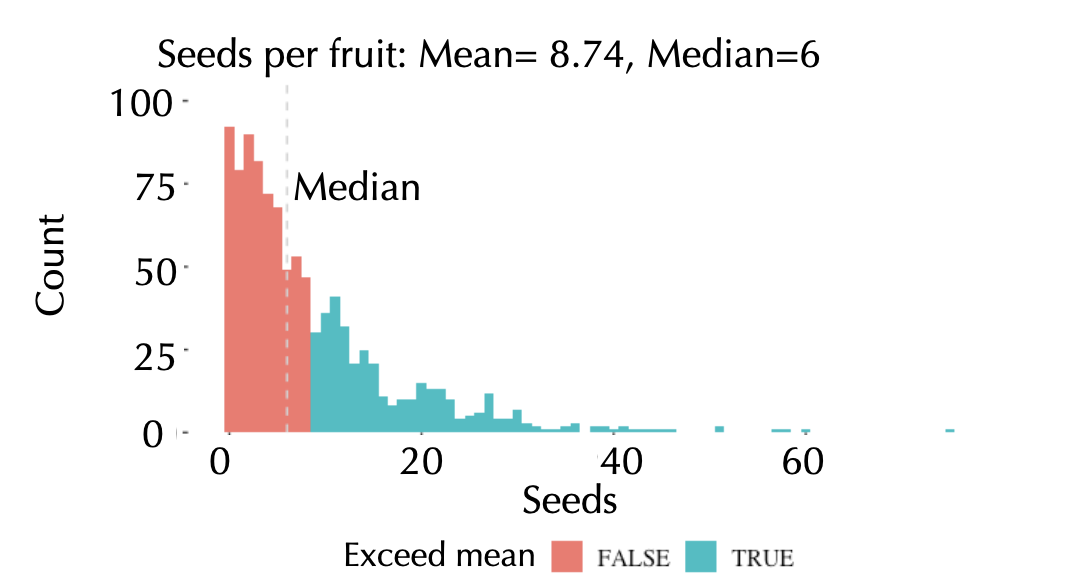
Mean or Median?
Number of seeds per fruit. Which one is better in this case?
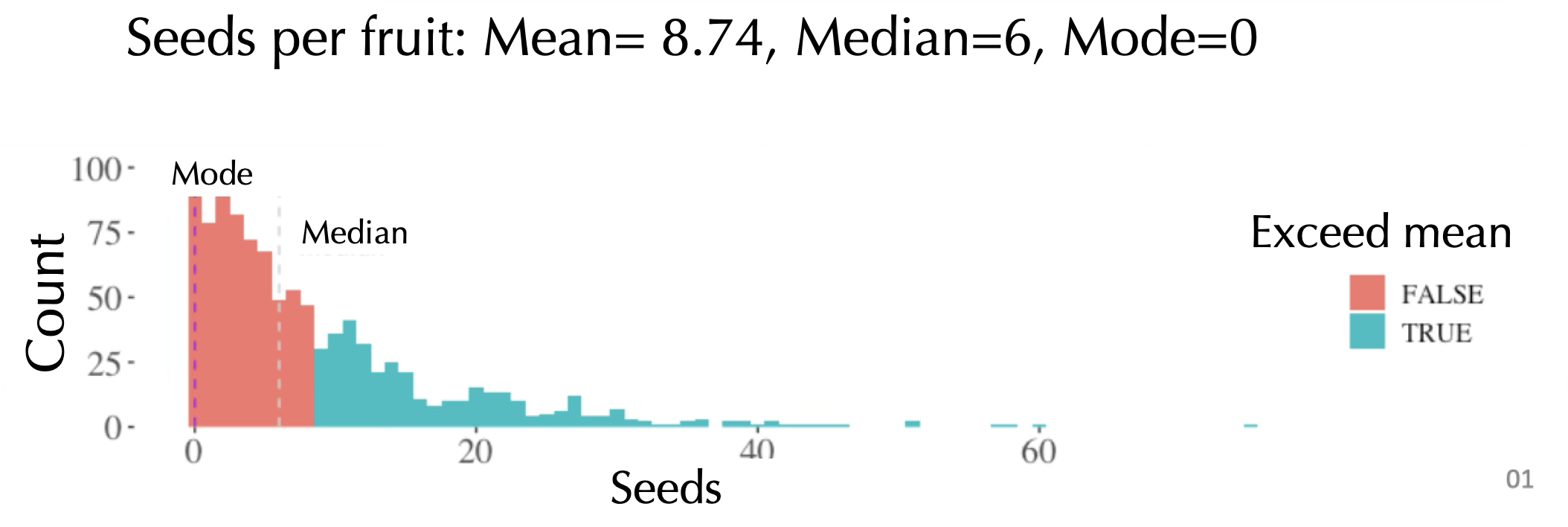
Mode
The most common value observed in a sample
easy to pick out as the peak in a histogram
Useful because it always reflects a value actually seen in the dataset, unlike mean and median
Skewness
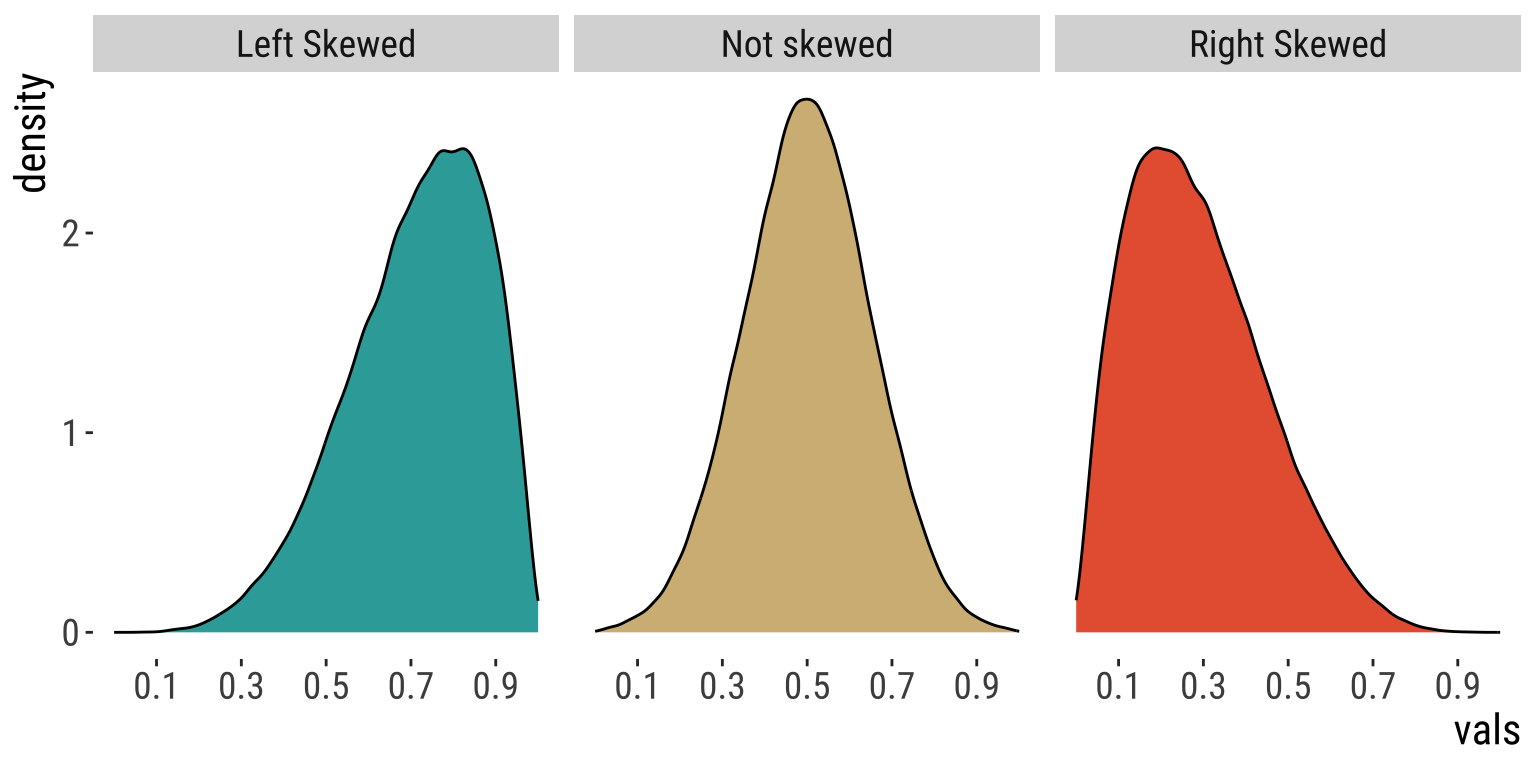
Skewness
Left: Asymmetric Few small values. \(>1/2\) of values exceed the mean.
Middle: Symmetric As many large as small values. \(\sim1/2\) of values exceed the mean.
Right: Asymmetric Few large values. \(>1/2\) of values are less than the mean.
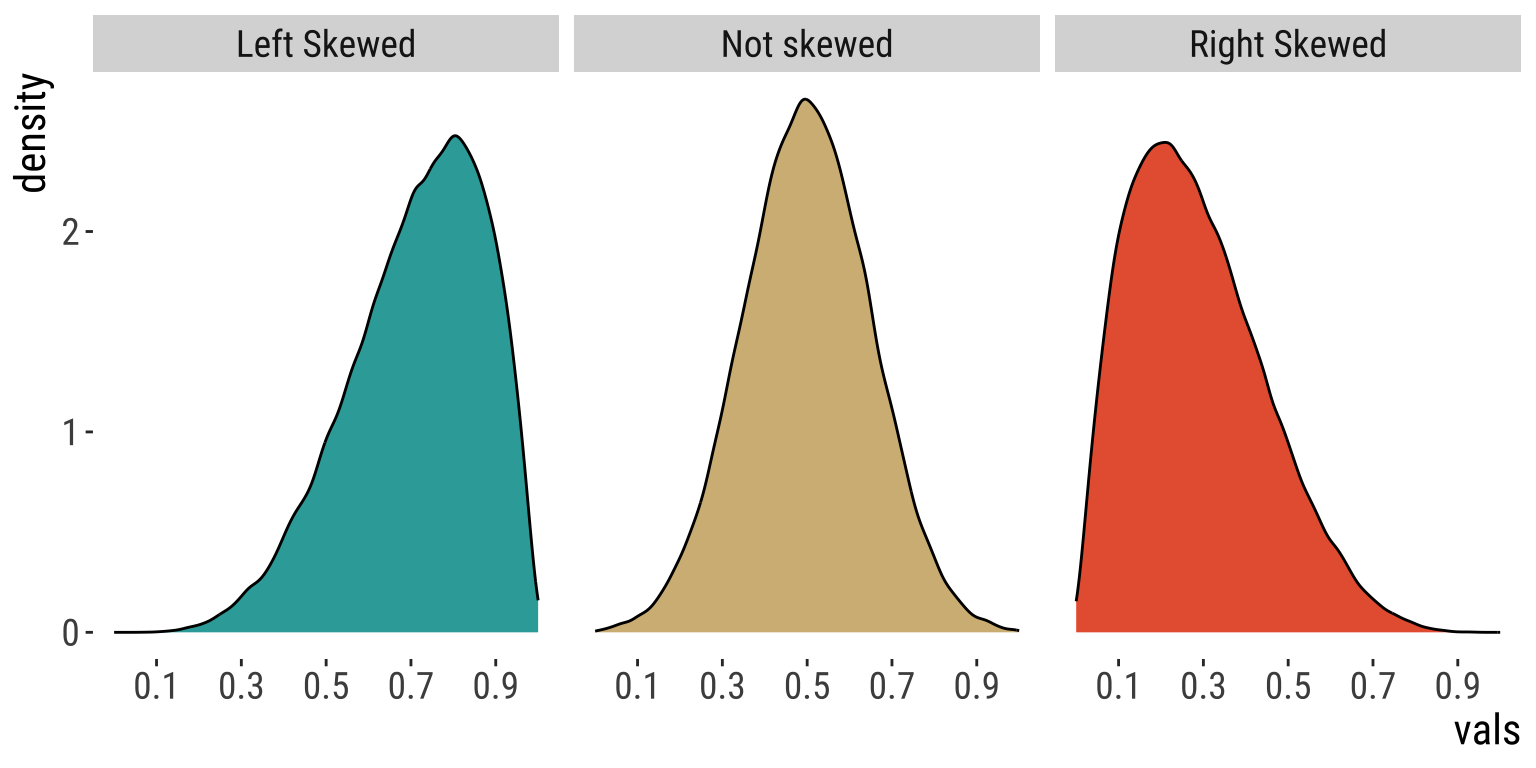
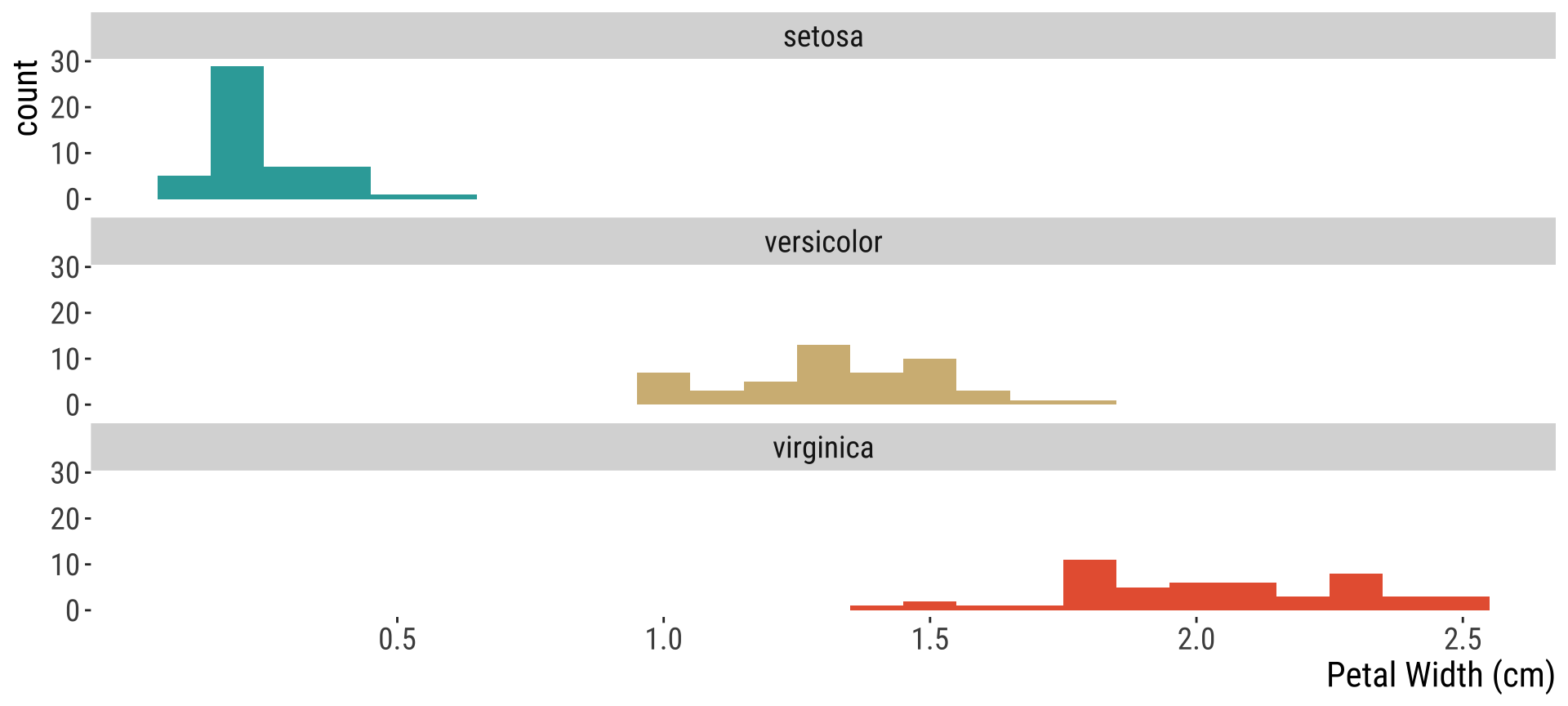
Histograms reveal measures of center
Recall the iris dataset

That’s all for today

From: makeameme.org