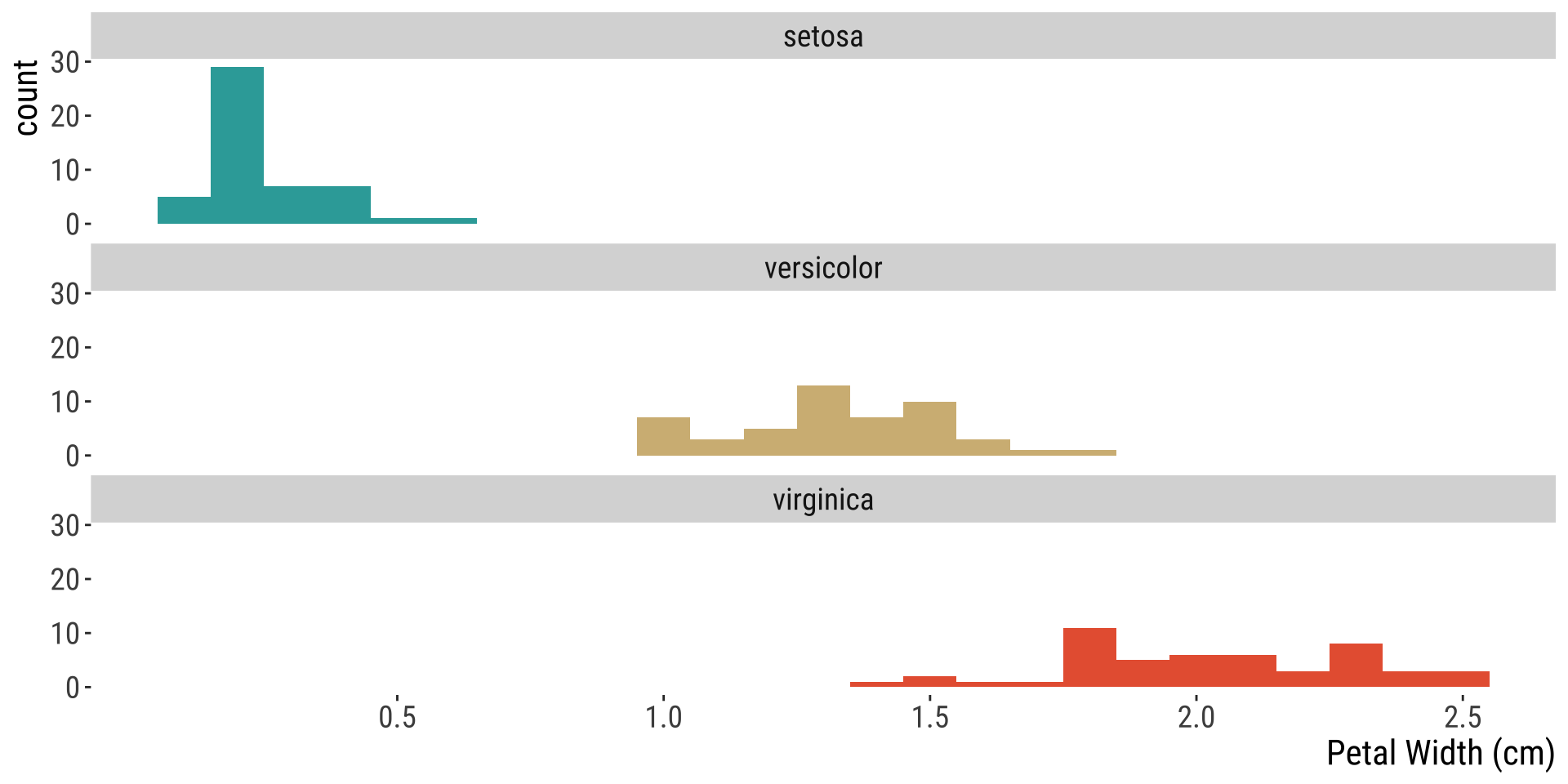
2.3.Displaying & Describing Data
Measures of spread and plots
2025-09-22
Range
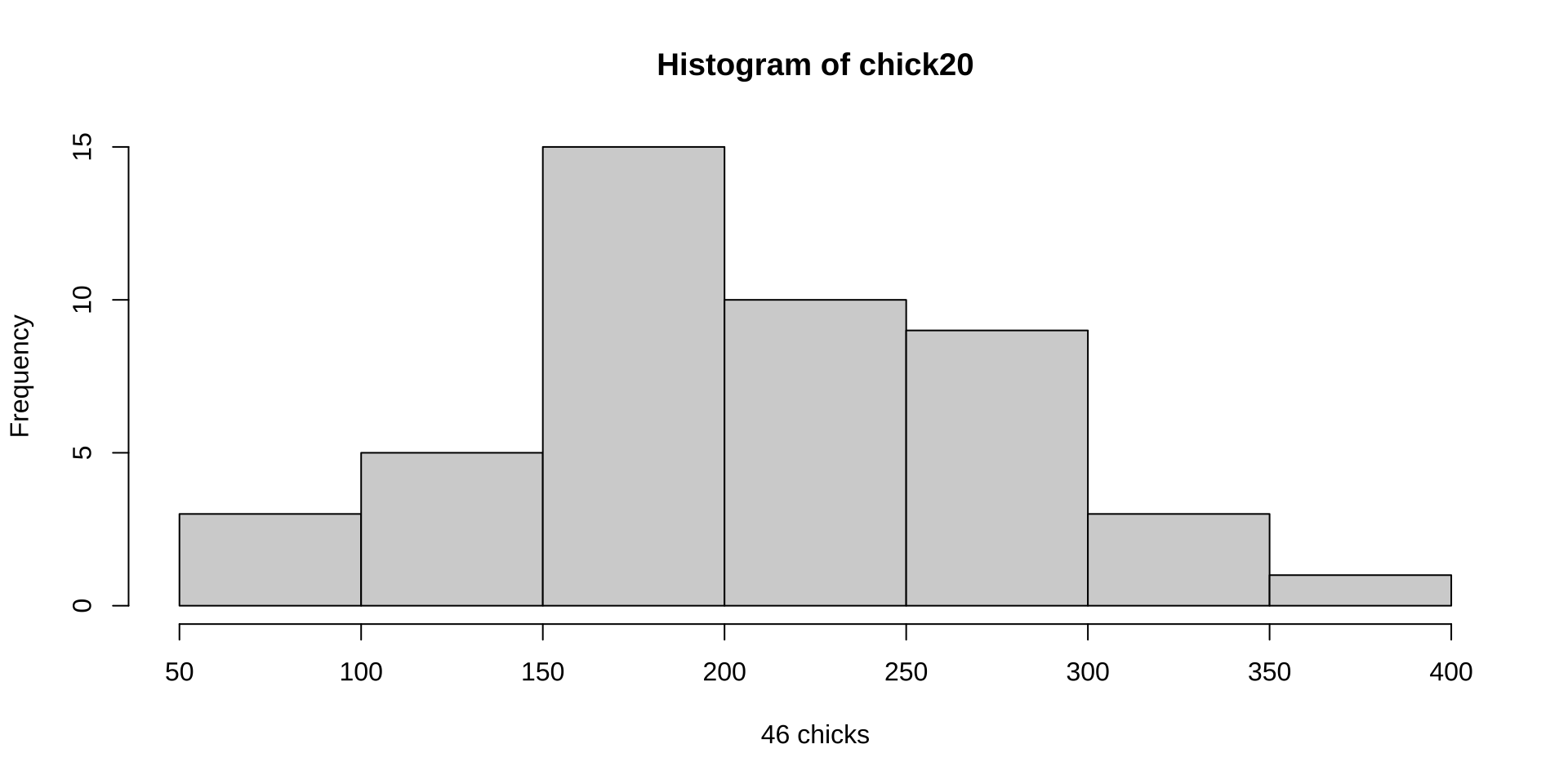
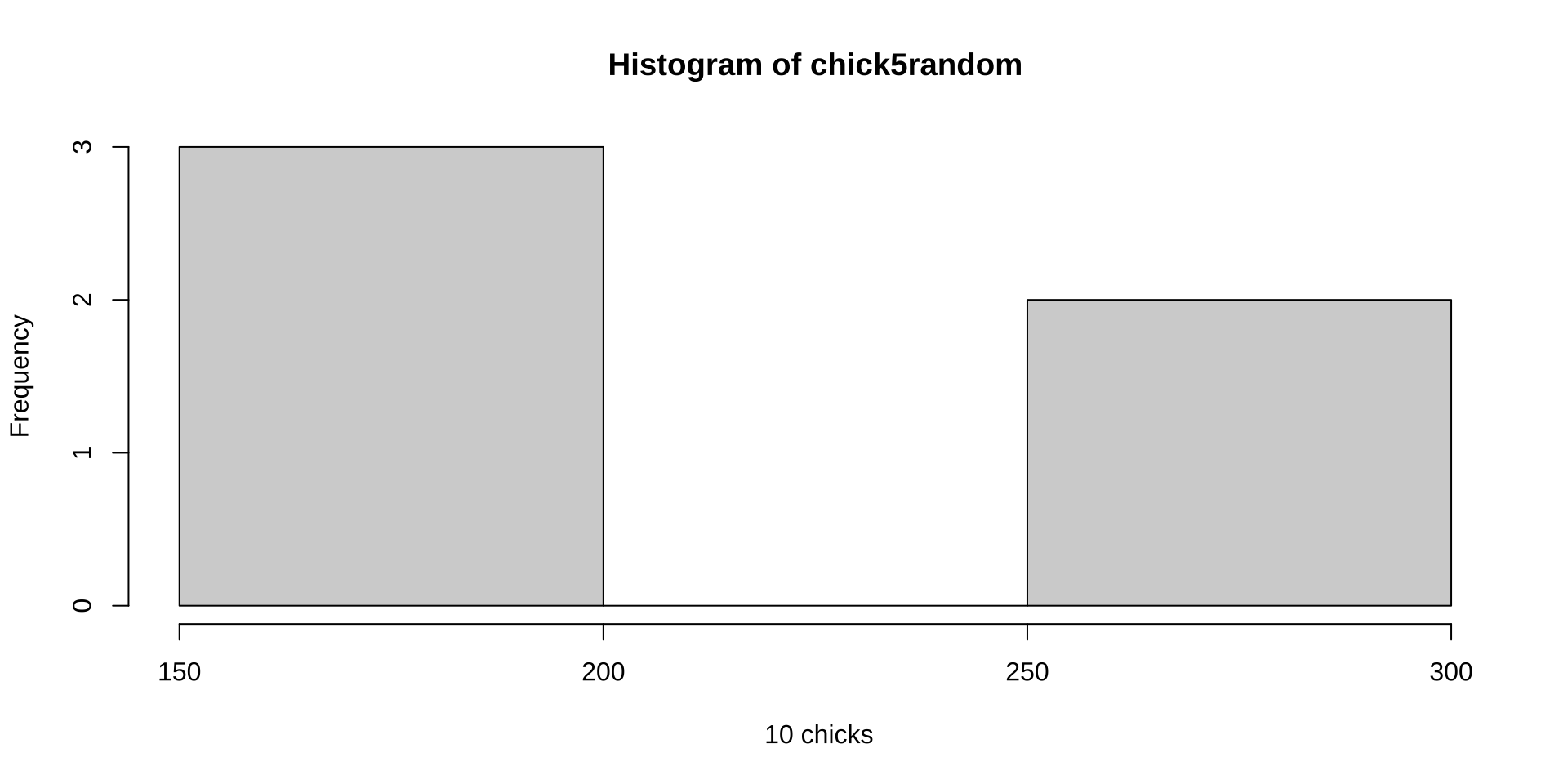
If I take a sample of just 5 chicks from those 46 …
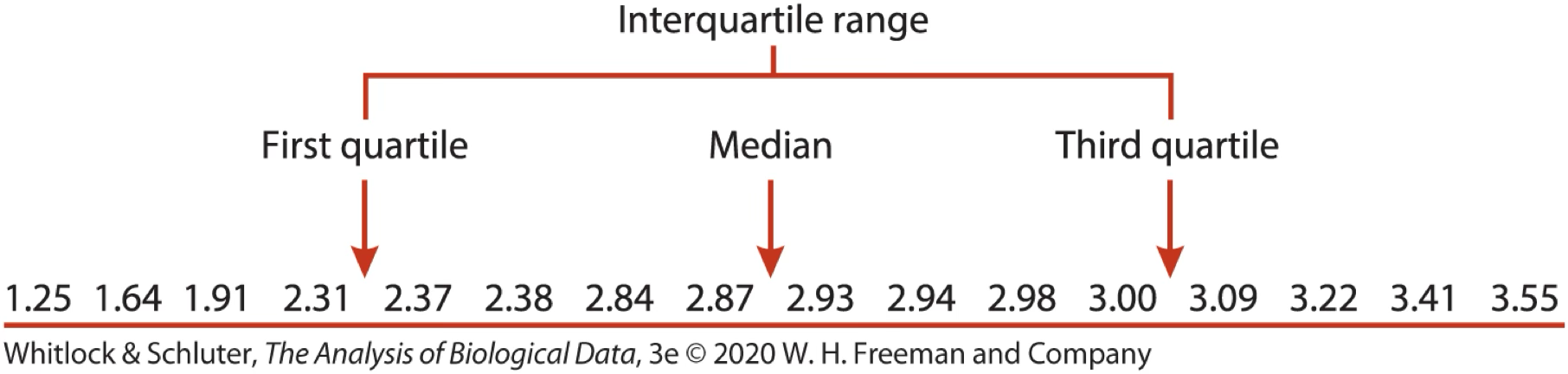
IQR
Imagine sorting your data.
- The individual in the middle is the median.
- The first and last individuals mark the range
- The other two quantiles are the individuals ¼ and ¾ the way into your sorted list of data
- The difference between these is the interquartile range
IQR Example
Example: Running speeds (cm/s) of Tidarren spiders before voluntary amputation of pedipalp
Attention:
- Quantiles partition the data into \(n\) parts
- Quartiles partition the data into quarters
IQR Example
\(n=16\)
1st quartile: \(j=0.25n=4\)
3rd quartile: \(j=0.75n=12\)
If \(j\) is integer, \(\frac{Y_{j}+Y_{j+1}}{2}\)
\(\frac{Y_{4}+Y_{5}}{2}=\frac{2.31+2.37}{2}=2.34\)
\(\frac{Y_{12}+Y_{13}}{2}=\frac{3+3.09}{2}=3.045\)
IQR in R
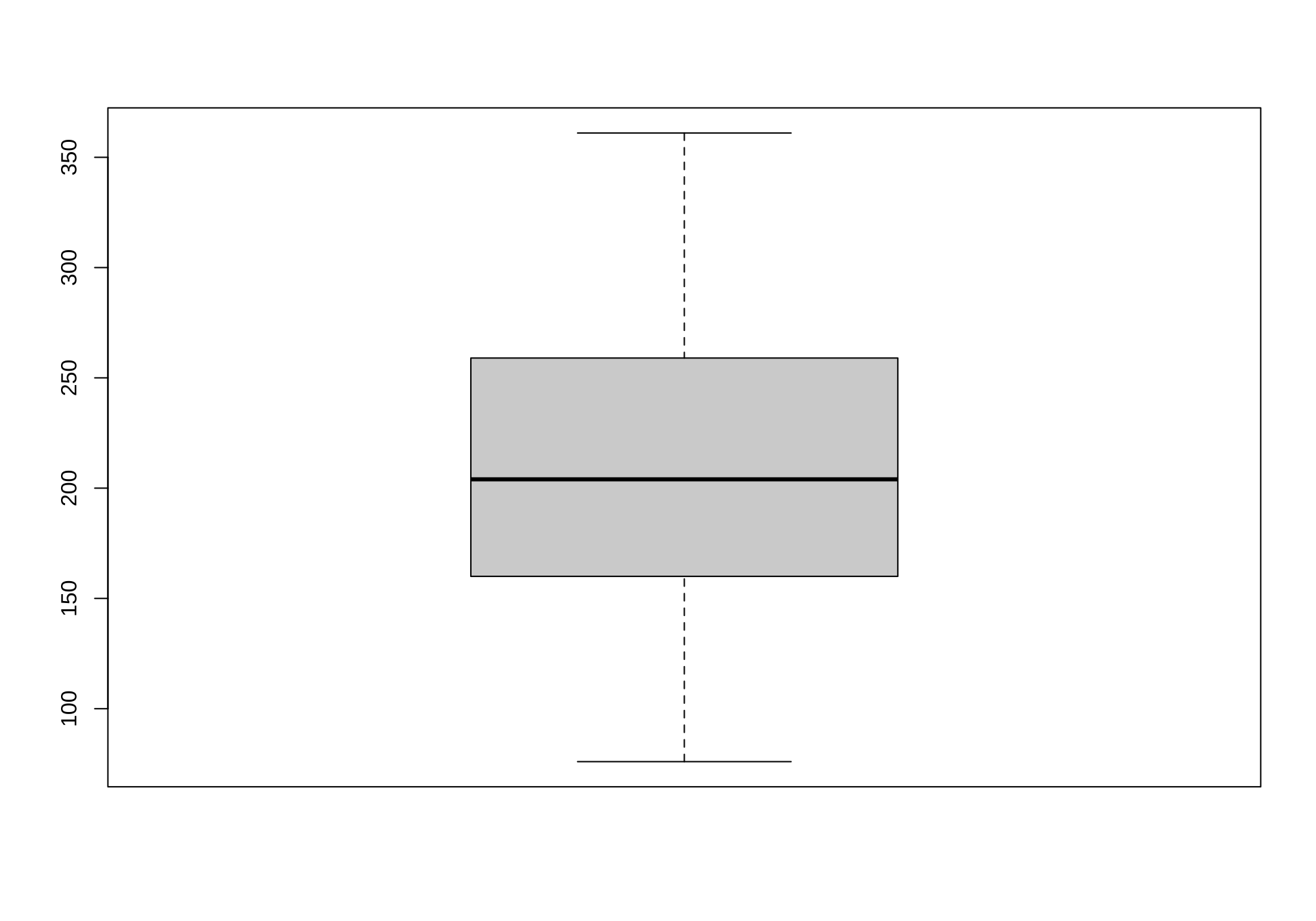
summary() gives quartiles and max/min
Min. 1st Qu. Median Mean 3rd Qu. Max.
76.0 161.0 204.0 209.7 259.0 361.0 The “long” route:
The shortcut
That’s all for today

From: makeameme.org