•Using \(\chi^2\) to test if data are distributed according to a Poisson distribution
Recap: Goodness of Fit Tests
Does data come from a given distribution with specified parameters?
Using the \(\chi^2\) statistic to test if data are Poisson distributed !
Why Poisson? (1/2)
We often want to know if events independent in time/space. E.g.:
Are some people lucky? ☘️
Do baseball players go on streaks? ⚾
Do cats stick together, or avoid one another? 🐯
Perhaps we can use real data and contrast it to expectations under a null model and test. What might that distribution look like?
Why Poisson? (2/2)
Assuming events are independent the Poisson distribution, the Poisson describes the expected probability of \(X\) of events (successes) in a block of time or space.
Poisson experiments (1/3)
Random Events in Time or Space
The number of successes in the experiment can be counted (discrete).
The mean number of events (successes) that occurs during a specific interval of time (or space) is known.
Each outcome is independent.
The probability that a success will occur is proportional to the size of the interval.
Poisson experiments (2/3)
Random Events in Time or Space
Example: Number of births per hour in a given hospital
The number of successes in the experiment can be counted (discrete).
The mean number of successes that occurs during a specific interval of time (or space) is known.
Each outcome is independent.
The probability that a success will occur is proportional to the size of the interval.
The Poisson distribution (1/)
Formally: a mathematical description of the probability of \(X\) successful outcomes when:
the number of attempts, \(n\), is high
the probability of success for each attempt, \(p\), is low and determined through a random process
the probability of each attempt, \(p\), is independent of prior success or failure
The Poisson distribution (2/)
The Poisson distribution describes the expected probability of \(X\) independent events in time/space.
The Poisson distribution (4/)
The Poisson distribution describes the expected probability of \(X\) independent events in time/space.
The Poisson Equation
Assuming events are random and independent, the probability of observing \(X\) events in a block of time or space equals:
\(P[X]\): probability of occurrence of \(X\) successes in one trial
\(\lambda\) (or \(\mu\)): the expected (mean) number of events in a block.
\(e\) is the base of \(ln()\), aka Euler’s number (a constant, exp(1) in R).
Poisson: Fish Example (1/) 🐟
Parasites are a major force in human health, as well as evolution, ecology, and agronomy, animal husbandry.
Shaw et al. asked if the distribution of parasites or across individual Shad fish was random, or if some have an exceptional parasite burden? Here are their data:
num_parasites
num_fish
0
103
1
72
2
44
3
14
4
3
5
1
6
1
7
0
8
0
9
0
Poisson: Fish Example (2/) 🐟
\(H_0\): Parasites are placed randomly on fish in a population i.e. parasite numbers follow a Poisson Distribution.
Poisson: Fish Example (3/) 🐟
\(H_A\): Parasites are not placed randomly on fish in a population i.e. parasite numbers do not follow a Poisson Distribution.
Steps in Hypothesis Testing
State hypotheses
Find expectations (via simulation or via model)
num_parasites
num_fish
0
103
1
72
2
44
3
14
4
3
5
1
6
1
7
0
8
0
9
0
total_fish
total_parasites
238
225
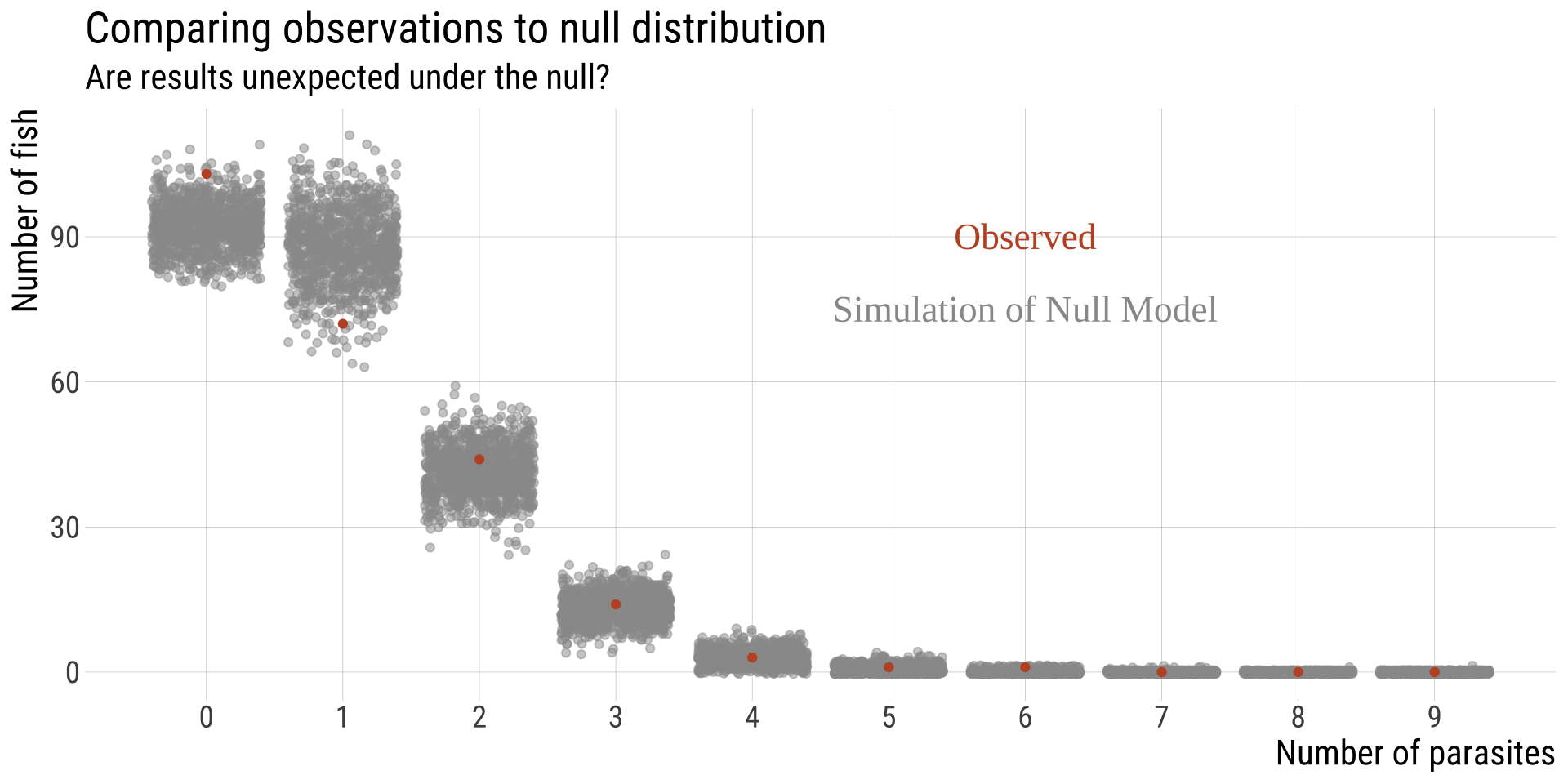
Option 1: A Lousy Simulation (1/) 🐟
We can put 225 on 238 fish many times to generate a null.
Take 225 parasites and:
randomly place one parasite in one of 238 fish
repeat for each parasite
the same fish can be the target more than once
At the end, count the number of parasites in each fish
Repeat this many, many times
Option 1: A Lousy Simulation (2/) 🐟
Note: the observed data does not include X > 6 but they are possible and are thus shown here.
Assuming \(\alpha=0.05\), we fail to reject the NULL hypothesis (\(P>\alpha\)). We cannot exclude the idea that parasites are distributed at random across fish.
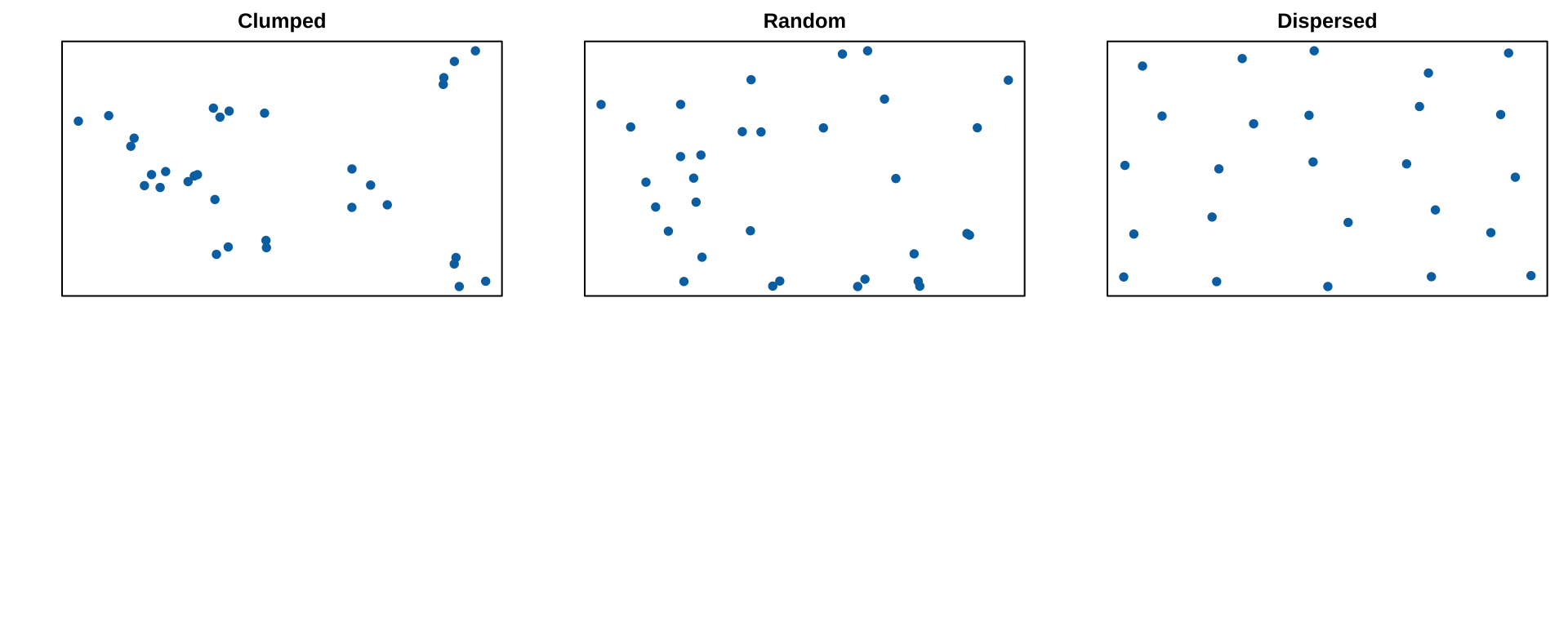
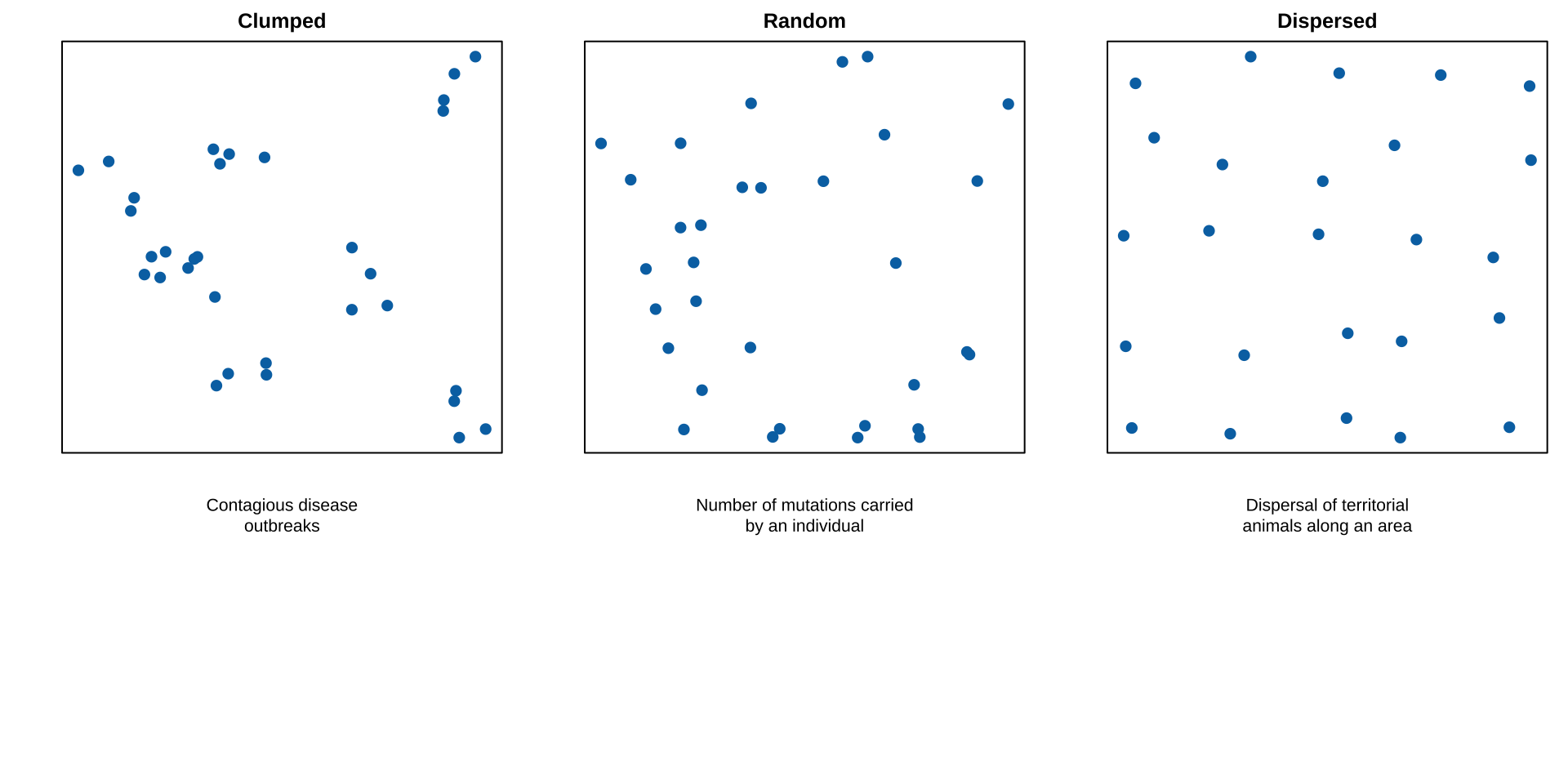
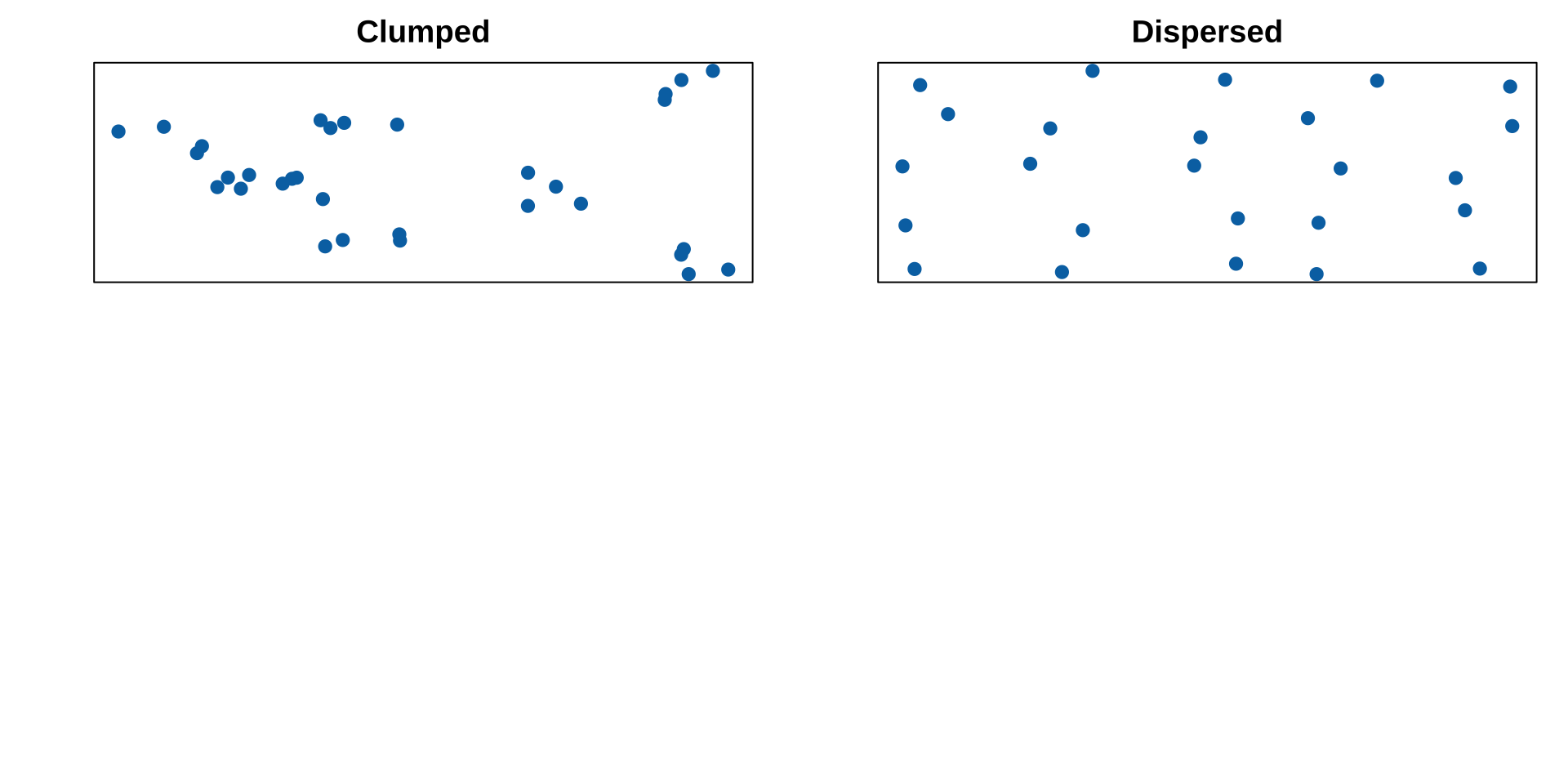
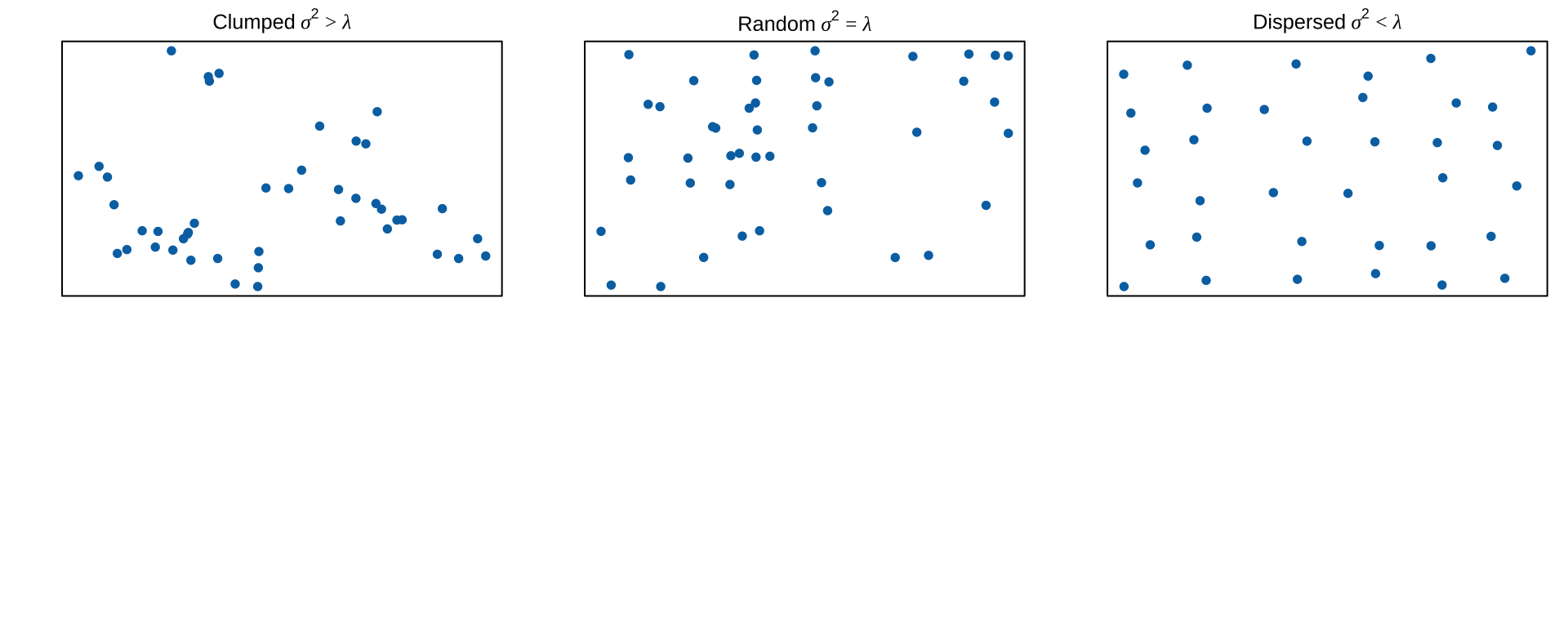
Are counts over or underdispersed
Over or underdispersed
A particular feature of the Poisson distribution is that the variance equals the mean.
Sample counts therefore vary more as the mean increases.
If the variance greatly exceeds the mean events are clumped
If the variance is much less than the mean events are dispersed.
Goodness of fit: Key points (1/)
A test of \(\chi^2\) goodness of fit compares the frequency distribution of a discrete or categorical variable with the frequencies expected from a probability model.
The test can be applied to many distributions
More general than the binomial test because it can handle more than two categories.
Goodness of fit is measured with the \(\chi^2\) test statistic. Its theoretical distribution is continuous. Probability is measured by the area under the curve.
The \(\chi^2\) distribution predicts the deviation of count data from expectations under \(H_0\).
Goodness of fit: Key points (2/)
• Proportional probability model: events fall in different categories in proportion to the number of opportunities. • The Poisson distribution model: describes the frequency distribution of successes in blocks of time or space when successes happen independently and with equal probability over time or space.
{kind=link}