9.1. Normal Distribution
Normal Distribution| Acknowledgments to Y. Brandvain for code used in some slides
2025-12-01
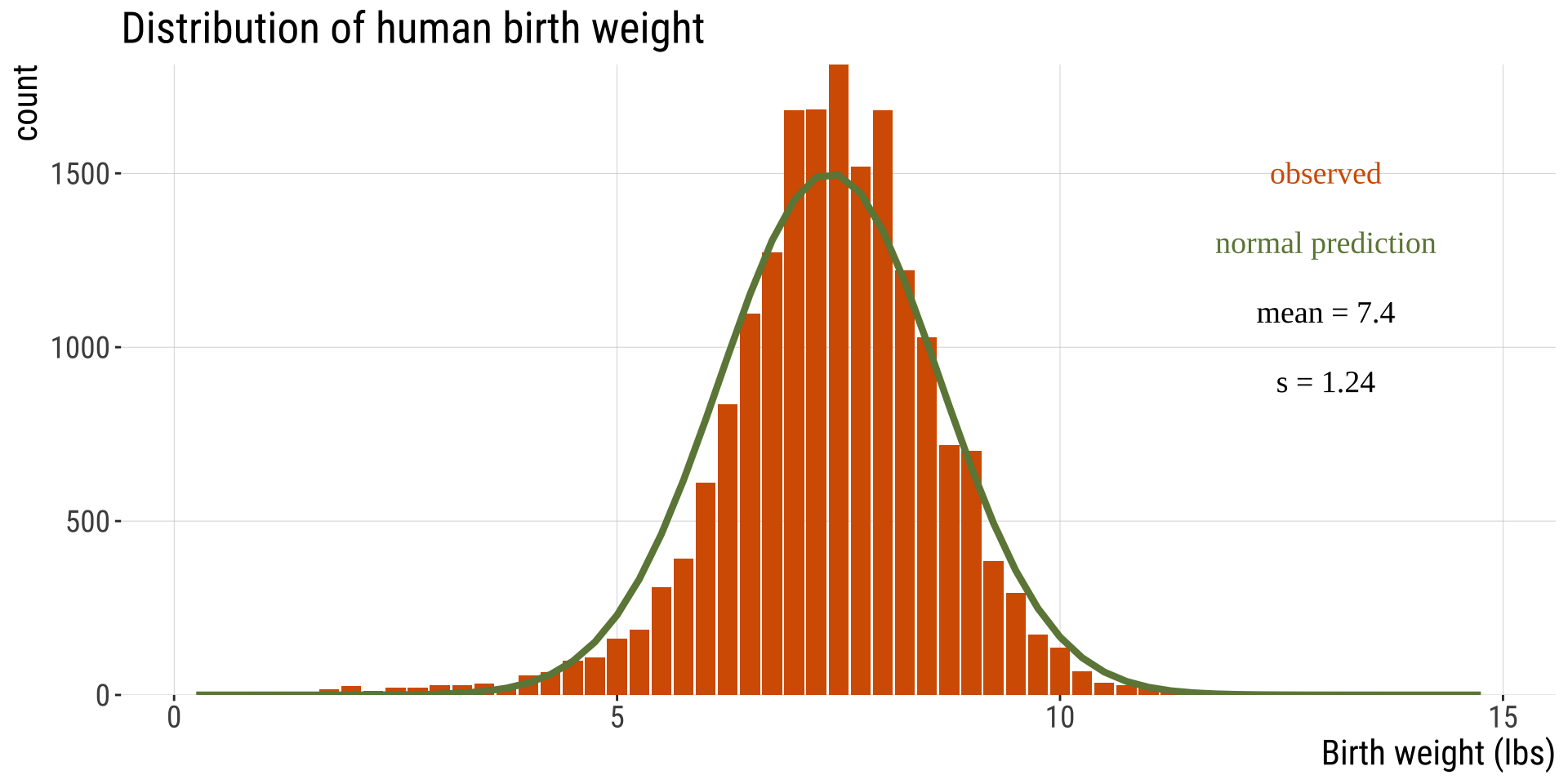
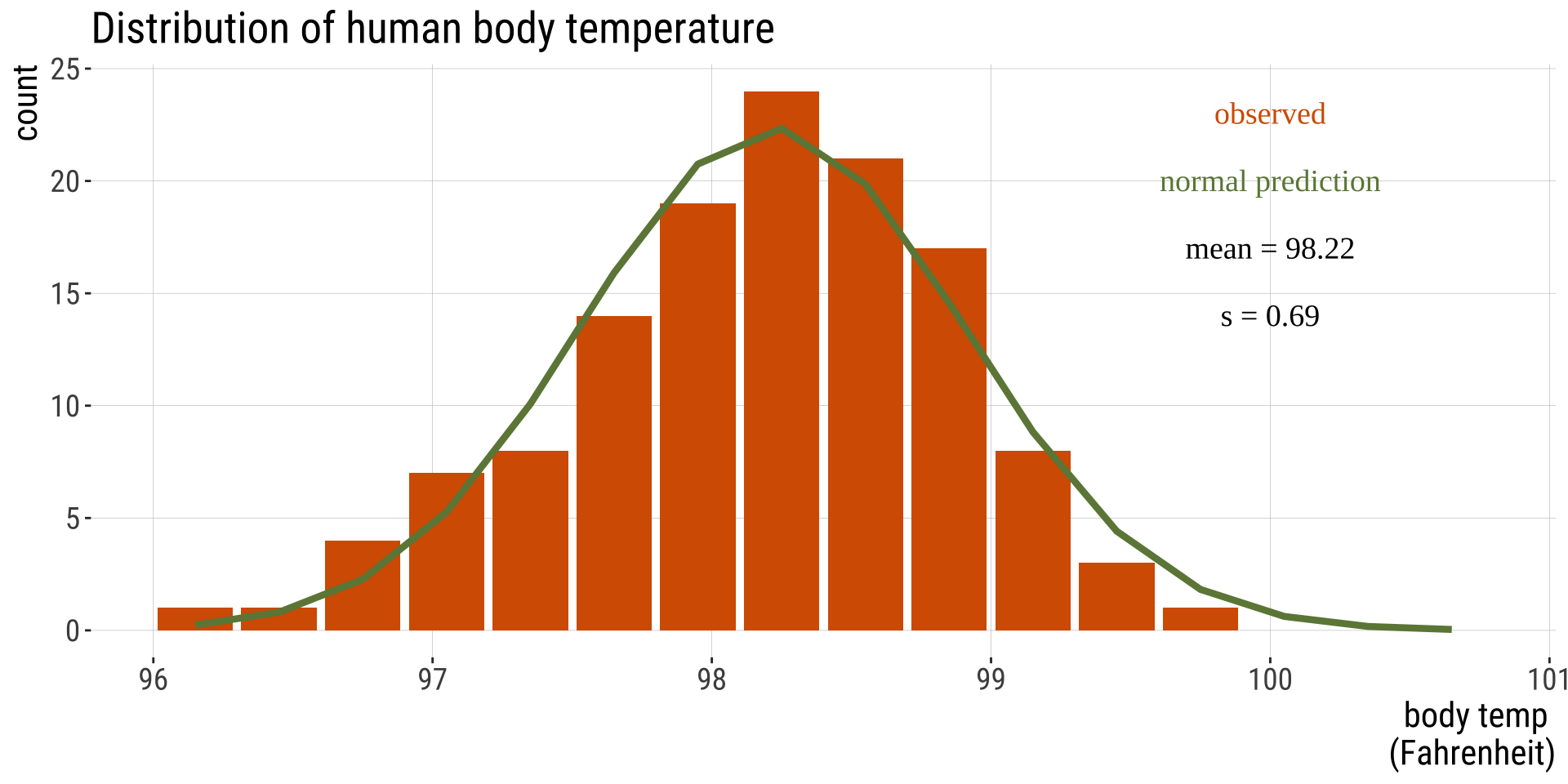
Human body temperature
- Body temp is (roughly) normally distributed
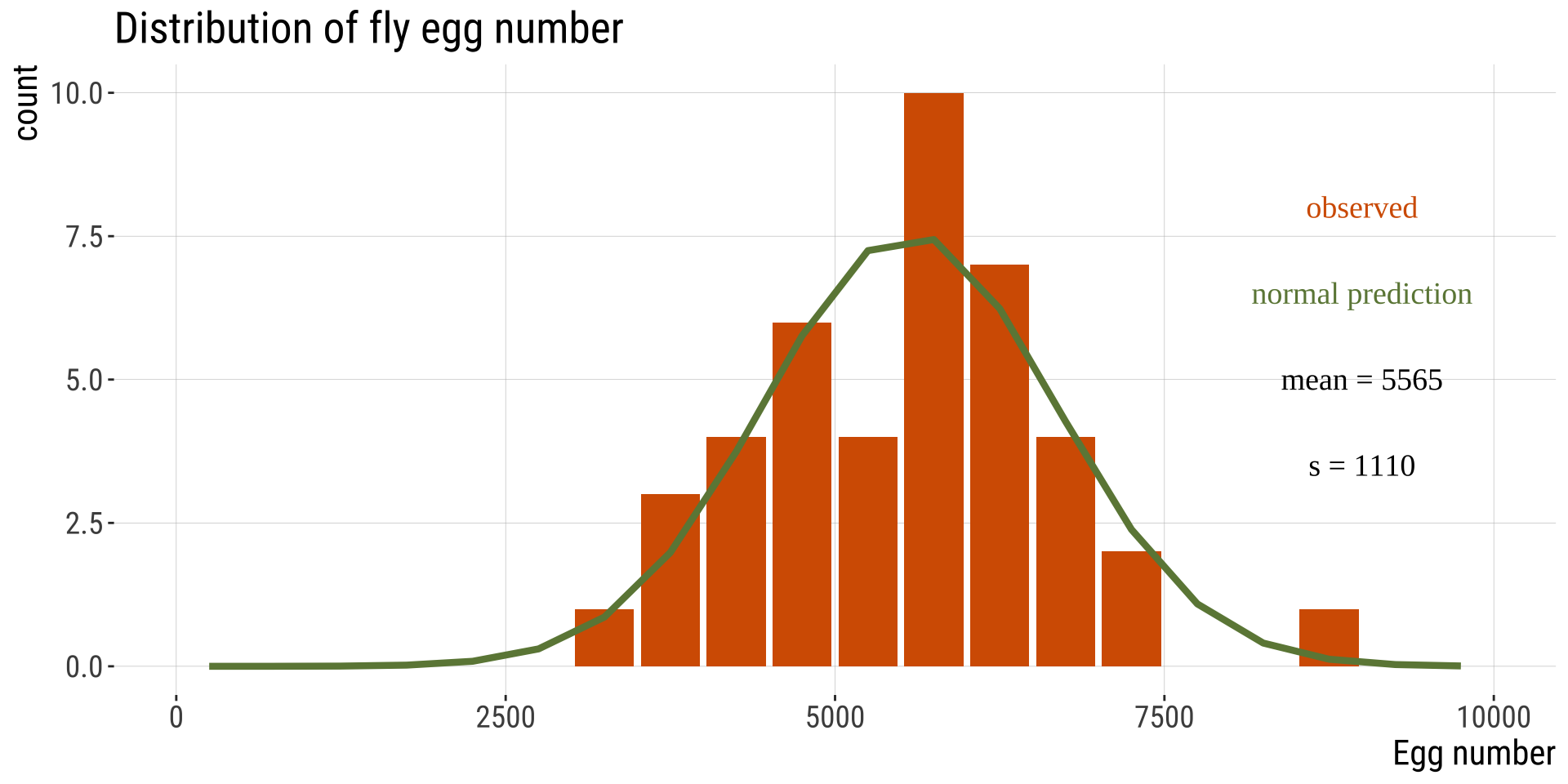
Drosophila egg number
- Drosophila egg number is (roughly) normally distributed
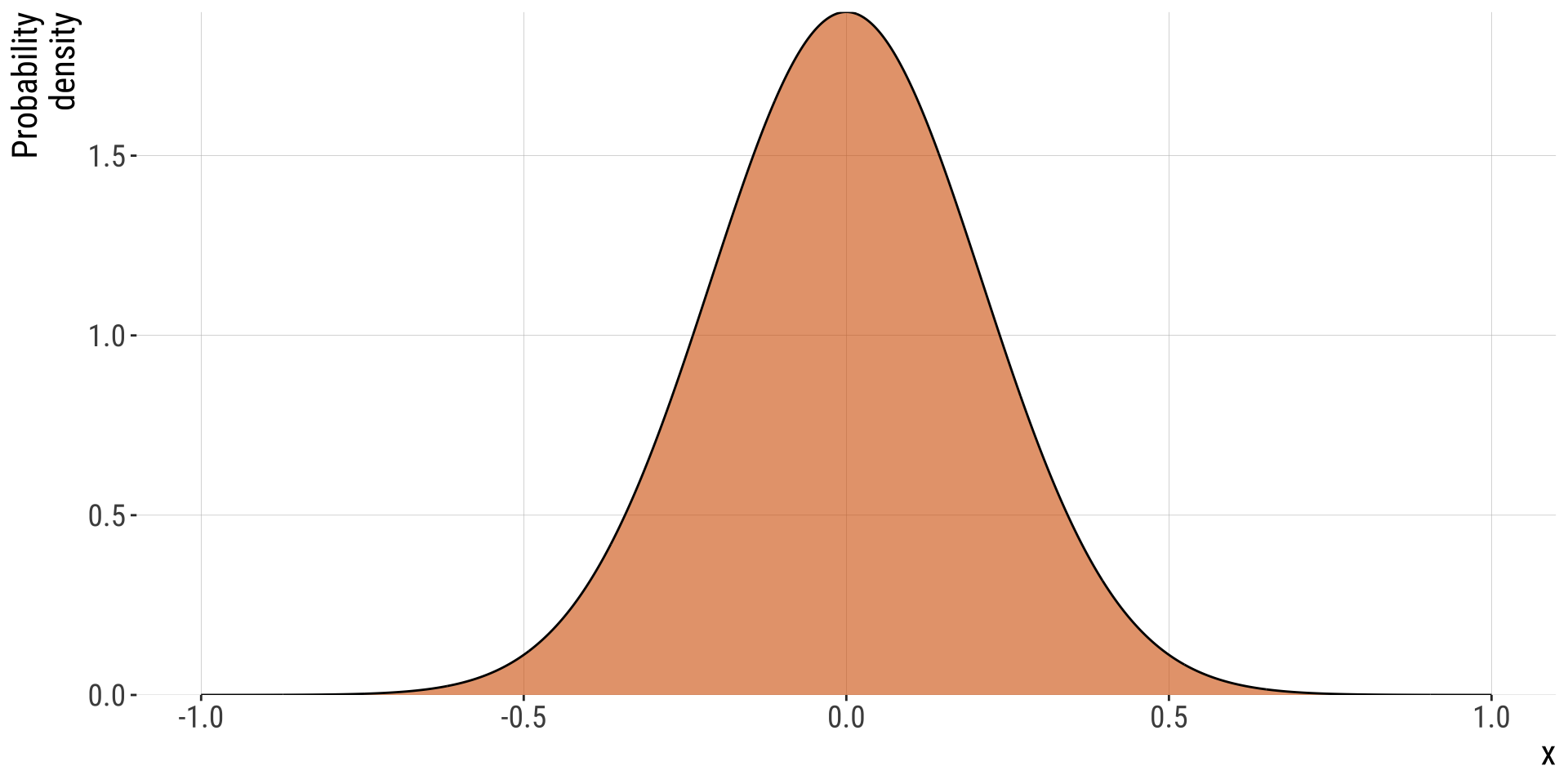
Concept check in (1/2)
- This normal distribution has points with a probability density > 1.
- We know that probabilities cannot be greater than 1, so how can this be the case?
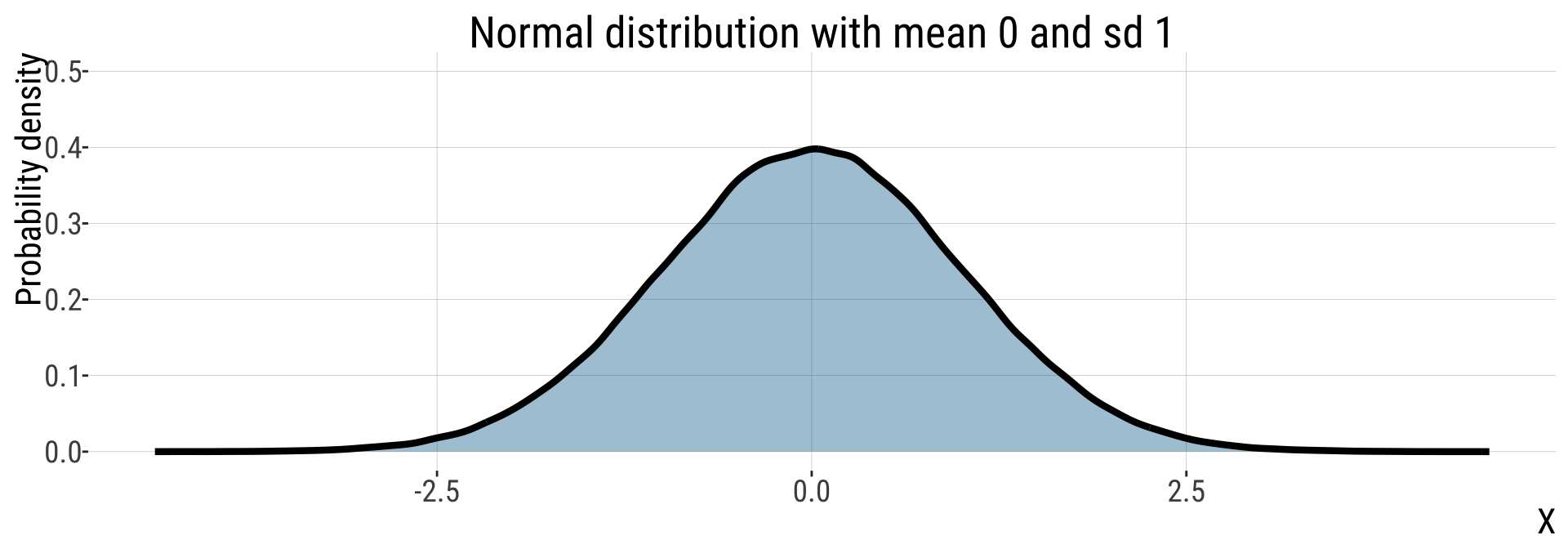
Parameters of the Normal Distribution (2/2)
- \(X\sim N(\mu, \sigma)\): \(X\) is normally distributed; normal is specified by \(\mu\) and \(\sigma\)
Visualizing Probability Densities
A Normal Distribution is symmetric around its mean
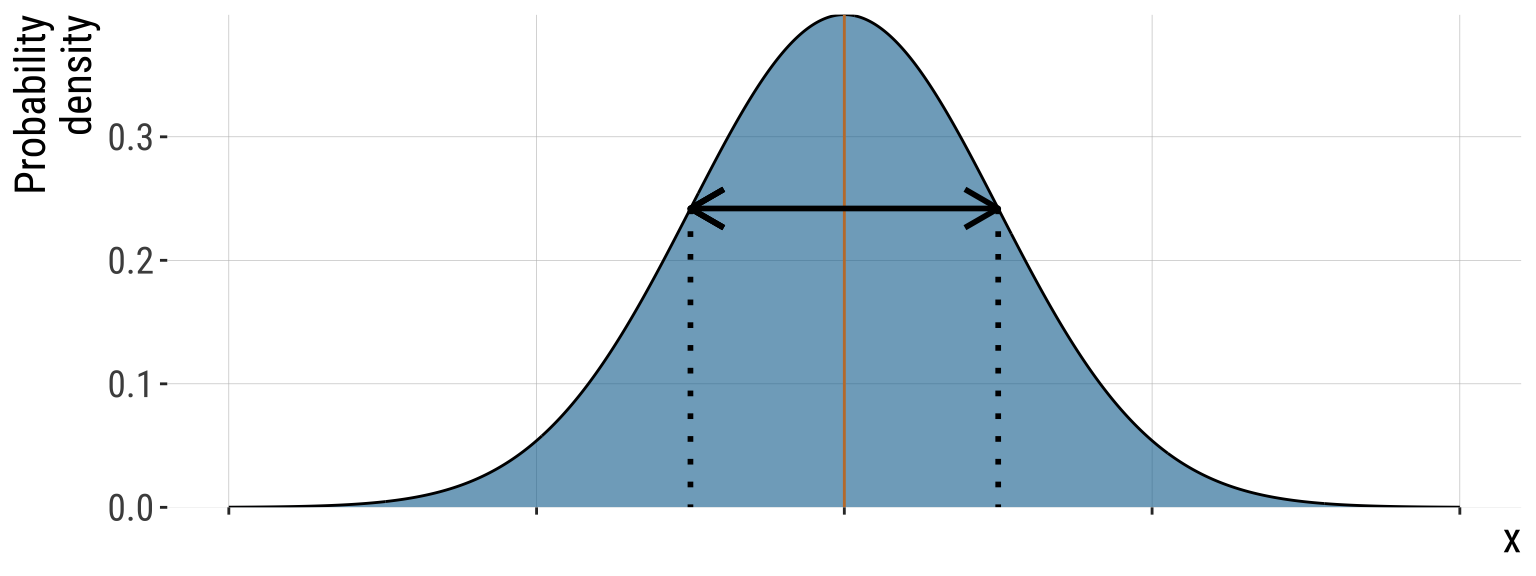
Probability that \(X\) falls in a given range (2/2)
- Some helpful (approximate) ranges:
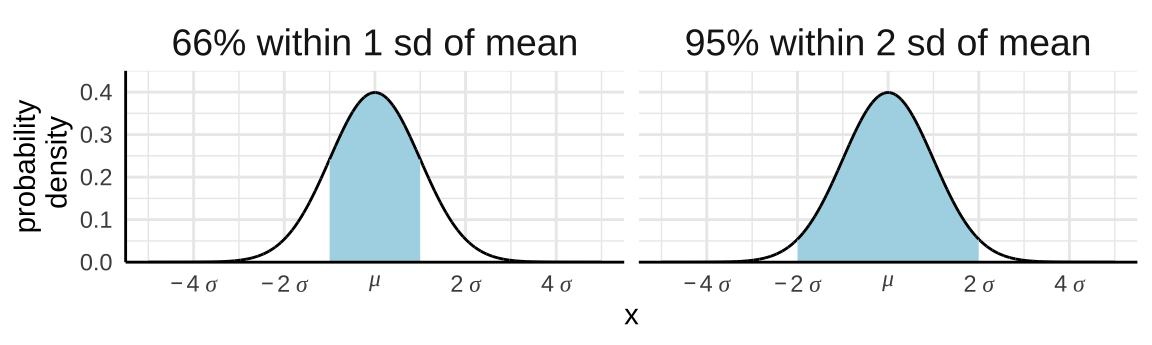
- These are approximations!
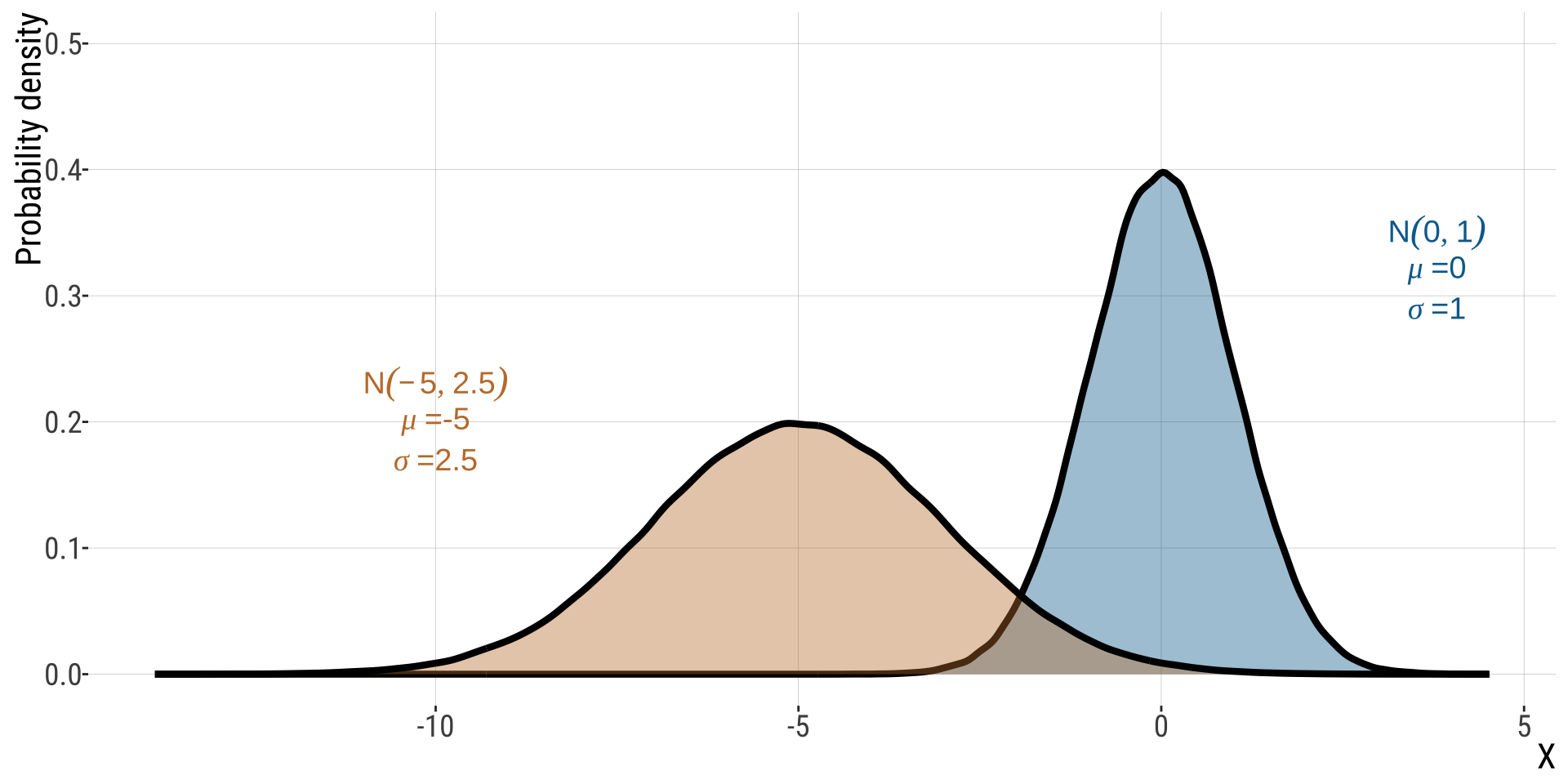
One Normal Distribution to Rule Them (2/2)
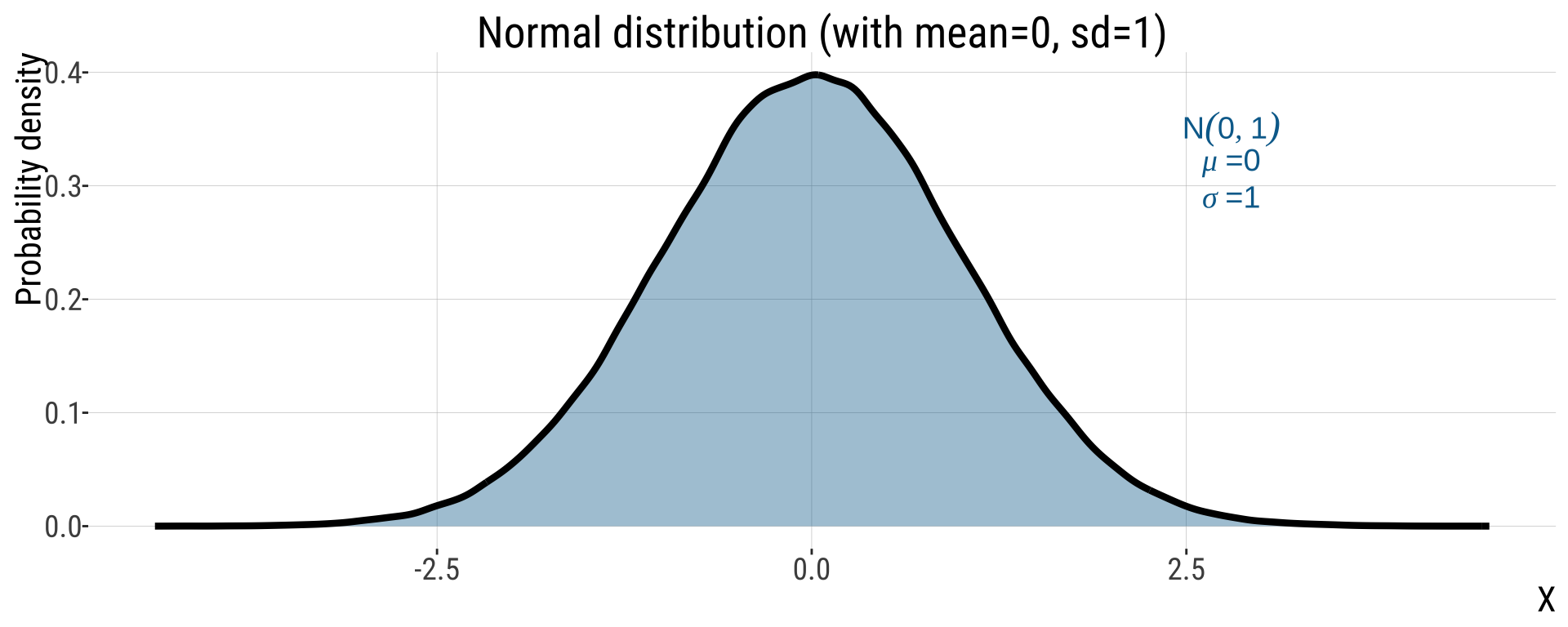
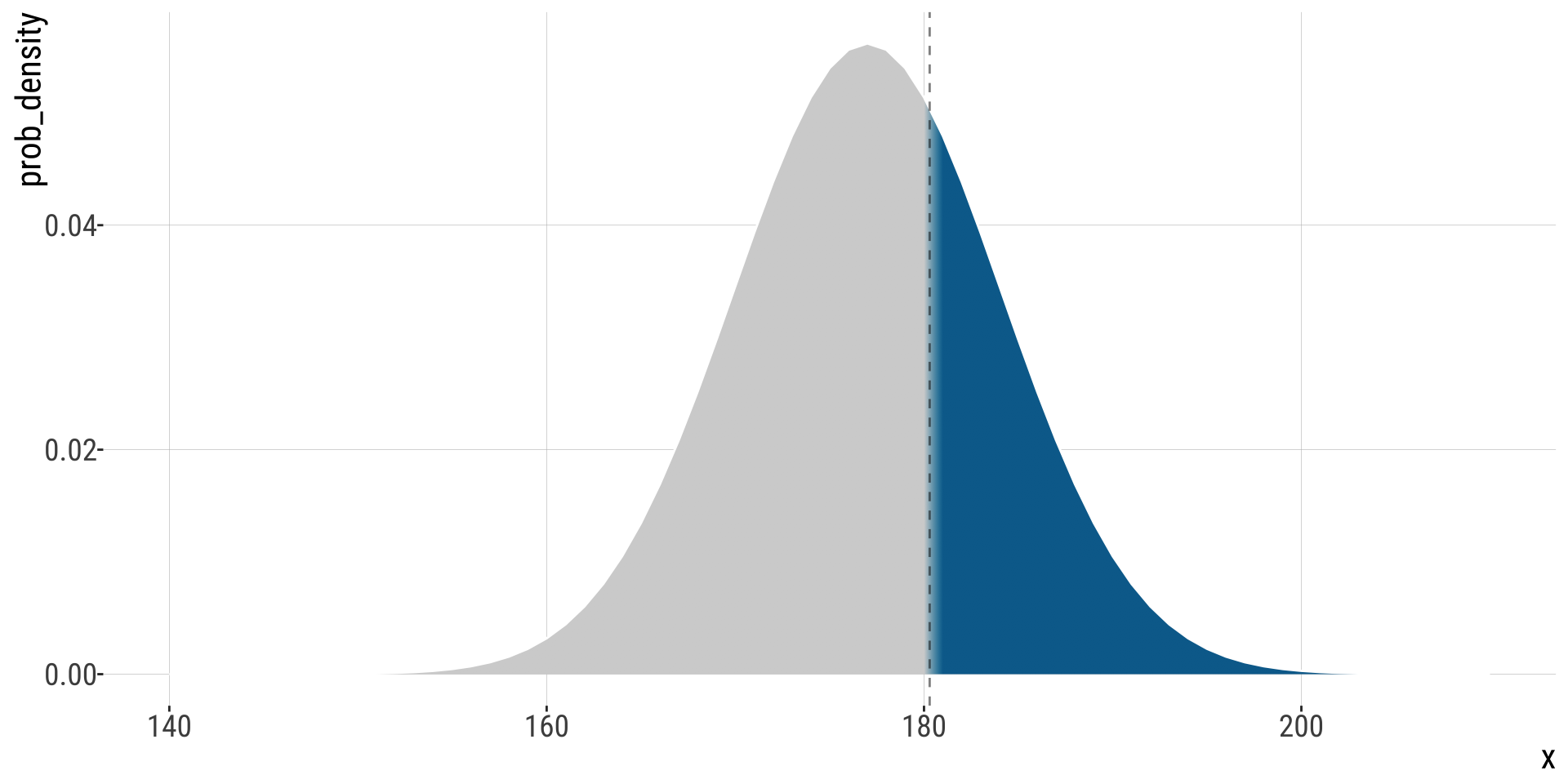
The \(Z\)-distribution
The \(Z\)-distribution describes the probability that a random draw from the standard normal is greater than a given value.
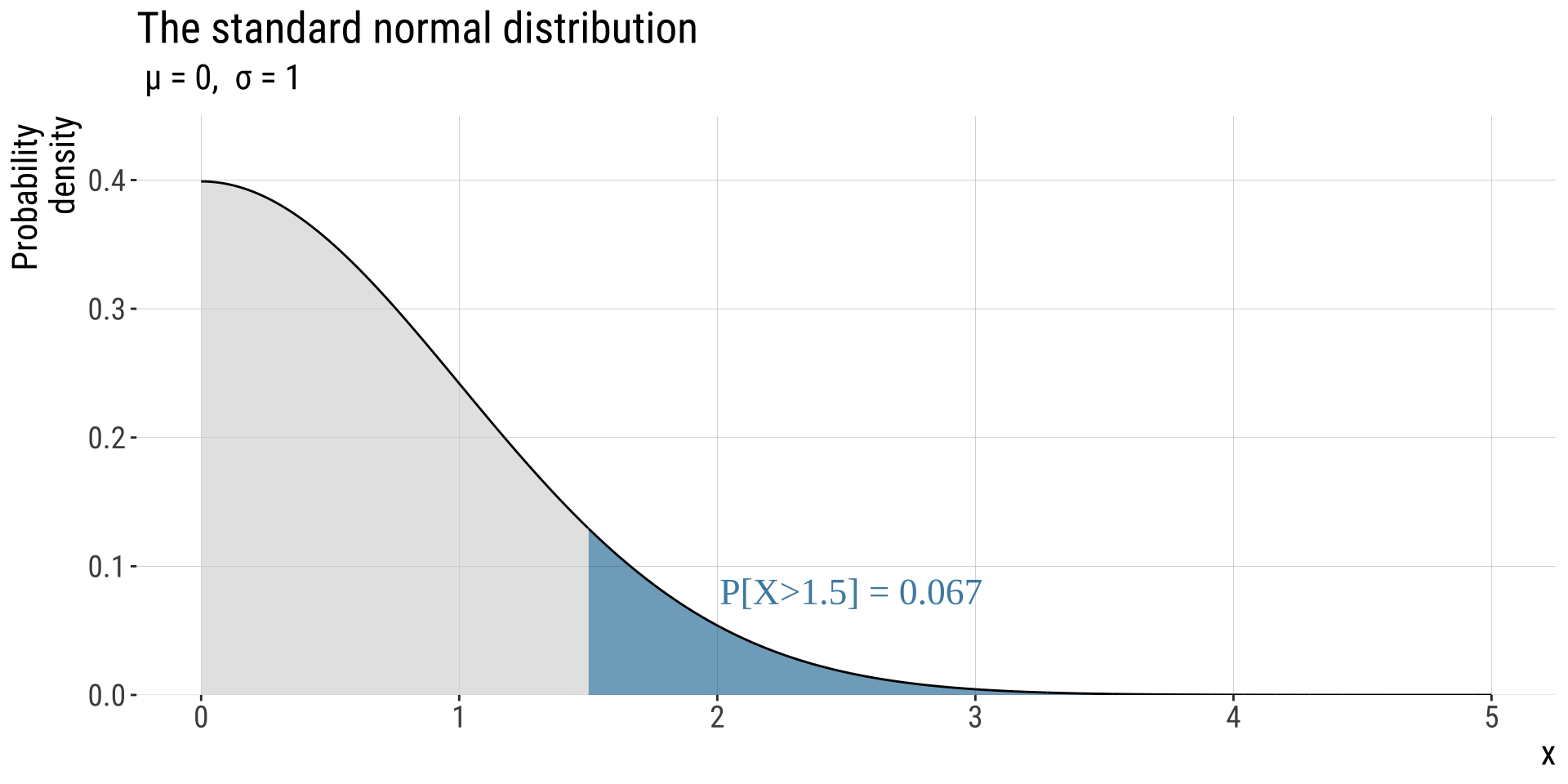
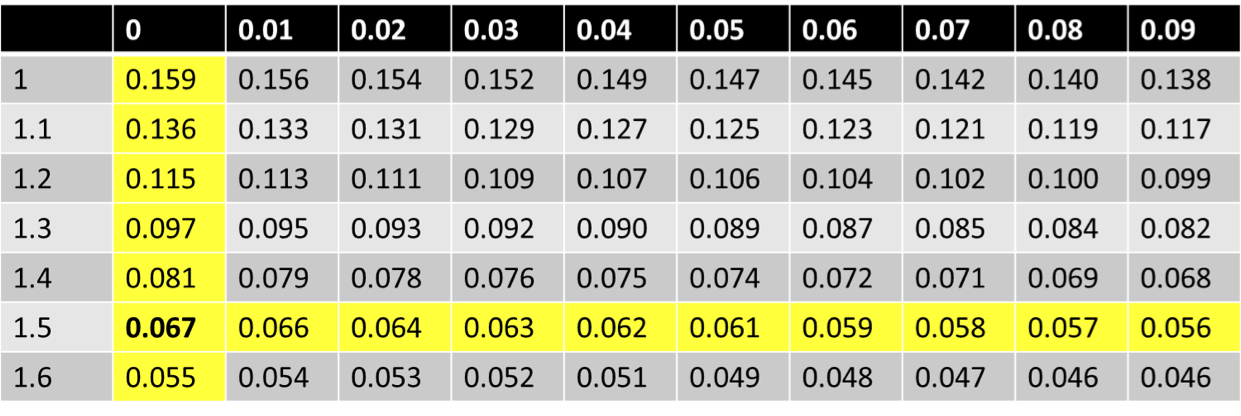
In R pnorm(x = 1.5, lower.tail = FALSE) = 0.067 In R: pnorm(q = 1.5, lower.tail = F): 0.0668
The Standard Normal Table (1/)
- We use the symbol \(Z\) to indicate a variable that has a standard normal distribution.
- The standard normal table: gives the probability of getting a random draw from a standard normal distribution greater than a given value
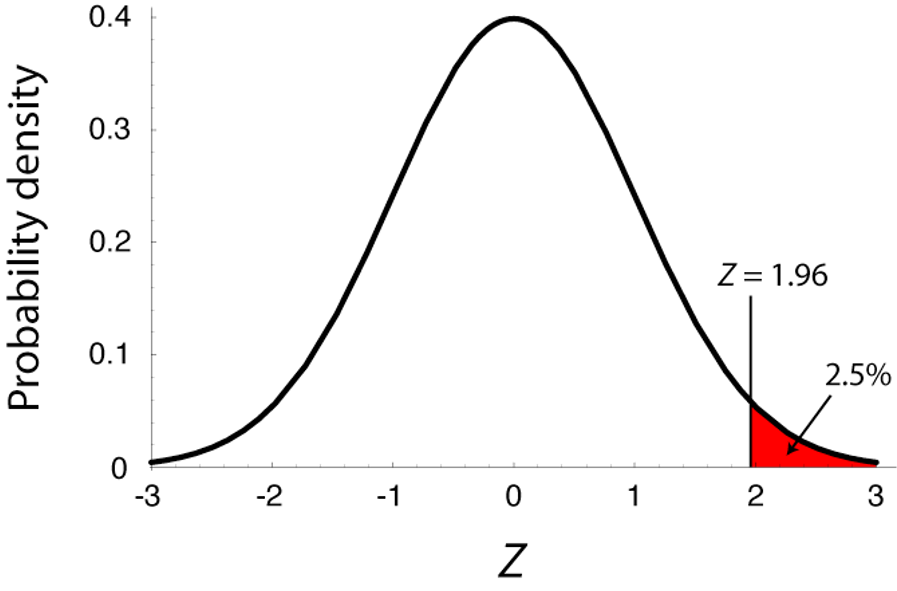
Figure 10.3-2 from textbook
The Standard Normal Table (2/)
- Rows contain the 1st two digits of Z
- Columns contain the 3rd digit
- The value is probability that a random draw from the standard normal is \(>Z\). E.g. \(P(Z>1.5)\)
British spies (3/)