elephants <- c(547, 551, 571, 567, 580)
c(mean(elephants), sd(elephants))
## [1] 563.20000000 13.86362146
t.test(elephants, alternative = "two.sided", mu = 525)
##
## One Sample t-test
##
## data: elephants
## t = 6.1612903, df = 4, p-value = 0.003522085
## alternative hypothesis: true mean is not equal to 525
## 95 percent confidence interval:
## 545.9860403 580.4139597
## sample estimates:
## mean of x
## 563.29.3. Normal Distribution
Normal Distribution
Bárbara D. Bitarello
2025-12-08
Key Learning Goals
- Explain the relationship between the t-distribution & the Z-distribution.
- Estimate uncertainty in the population mean from a normally distributed sample of size n.
- Know when/how to conduct a 1-sample t-test.
- Come up with mean values under the null.
- Estimate uncertainty in variability.
Recap
- \(Z\) and \(t\) distributions are not the same
- As sample size increases, \(t\) becomes more similar to \(Z\)
What do we use the t-distribution for?
- Confidence intervals
- Hypothesis testing
Recap elephant CI example
- Five elephants that gave birth after 547, 551, 571, 567, 580 days pregnant.
- How confident are we about our mean estimate here? Let’s find the 95% CI.
\(95\%\text{ CI } = 563.2 \pm (t_{\alpha(2),4} \times 6.2)\)
\[ = 563.2 + (2.776445 \times 6.2)=580.41\] \[ = 563.2 - (2.776445 \times 6.2)=545.986\] \[545.99<\mu<580.41\]
One sample t-test
The one-sample t-test compares the mean of a random sample from a normal population with the population mean proposed in a null hypothesis.
Test statistic for one-sample t-test:
\[t=\frac{\bar{Y}-\mu_{0}}{s/\sqrt{n}}\]
\(\mu_{0}\) os the hypothesized population parameter (aka the mean value stated in the \(H_{0}\)).
Back to the elephants (1/)
Assume we know that elephant gestational period is normally distributed with \(\mu=525\) days. We already know that our 95% CI (last lecture) does not include that value, suggesting we will reject the null here through formal testing, but let’s do it anyway.
\(H_{0}\): This sample of elephants came from a population with \(\mu=525\) days of gestation.
\(H_{A}\): This sample of elephants did NOT come from a population with \(\mu=525\) days of gestation.
Back to the elephants (2/)
Recall: \(n=5, \mu_{0}=525, \bar{Y}=562.2, s=13.86\)
\(t=\frac{\bar{Y}-\mu_{0}}{s/\sqrt{n}}=\frac{563.2-525}{13.86/\sqrt{5}}=6.16\)
\(t_{0.05(2),4}=2.78\): \(0.01<p<0.001\)
Conclusion: we reject that null hypothesis that the population mean is \(525\) days.
In R
Assumptions of the One-sample t-test
- Random samples
- Independent Samples
- Normally distributed values
- Or, more precisely, normally distributed sampling distributions.
Some practice problems for later
Alternatives to the one-sample t-test
- Permutations (for hypothesis testing)
- Bootstrap (for estimating uncertainty)
- Non-parametric tests. E.g. sign test – i.e. a binomial test asking if the proportion of observations > μ0 differs from ½.
Parametric vs Nonparametric tests (1/)
- Parametric tests are statistical tests that make specific assumptions about the data.
- They assume the data follows a particular distribution, usually the normal distribution.
- These tests need the measurement scale to be interval or ratio.
- Parametric tests use population parameters like the mean and standard deviation in their calculations.
- E.g. t-test (one and 2 sample), ANOVA.
Parametric vs Nonparametric (2/)
- Nonparametric tests are statistical tests that do not assume a specific distribution for the data.
- They are used when data do not meet the assumptions of parametric tests, like normality.
- These tests are often used with ordinal data or when sample sizes are small.
- They may, for example, compare medians instead of means.
- E.g. Chi-square test, Mann–Whitney U test, Wilcoxon signed-rank test, Spearman’s rank correlation
Parametric vs Nonparametric tests (3/)
Parametric Pros:
- When assumptions are met, can detect differences more easily.
- Give estimates of population parameters.
- Handle more complex models, like regression or ANOVA.
Parametric Cons:
- Need assumptions such as normality and interval data.
- Extreme values can distort results;
- When the sample size is small, the normality assumption may be violated.
Parametric vs Nonparametric tests (4/)
Nonparametric Pros:
- Do not need normal distribution or homogeneity of variance.
- Less affected by extreme values.
- Can be used with smaller sample sizes.
Nonparametric Cons:
- Generally have less statistical power compared to parametric tests.
- Only test for differences in medians or ranks, not means.
- Fewer tests available for complex designs.
Is it normal?
Is it normal? (1/)
- A lot of the statistics we’ve been learning relies on the “normality” of the data
- While there are statistical procedures to test the null hypothesis that data come from a normal distribution, we almost never use these because a deviation from a normal distribution can be most important when we have the least power to detect it.
- For that reason,we usually use our eyes (believe it or not), rather than null hypothesis significance testing to see if data are approximately normal.
Is it normal? (2/)
- Few variables in biology show a perfect match to a normal distribution
- There are methods (e.g., QQplots) to assess whether you believe the assumption holds
- A method is robust if the answer it gives is not senstitive to modest departures from the assumption
- How do you know if a method is robust? This is a more advanced discussion we won’t go into, but, basically, we can assess this through computer simulations
“Quantile-Quantile” plots and the eye test (1/)
- The qqplot is a visual way of assessing whether our data are normally distributed by comparing the quantiles of our z-transformed data to those expected under a “perfect” Normal distribution
- In a “quantile-quantile” (or QQ) plot \(x\) is \(y\)’s \(z\)-transformed expectation, i.e.:
mutate(data, qval = rank(y)/(n+.5), x = qnorm(qval)), and \(y\) is the data.
“Quantile-Quantile” plots and the eye test (2/)
Recall the button pressing time example: a non-normal distribution
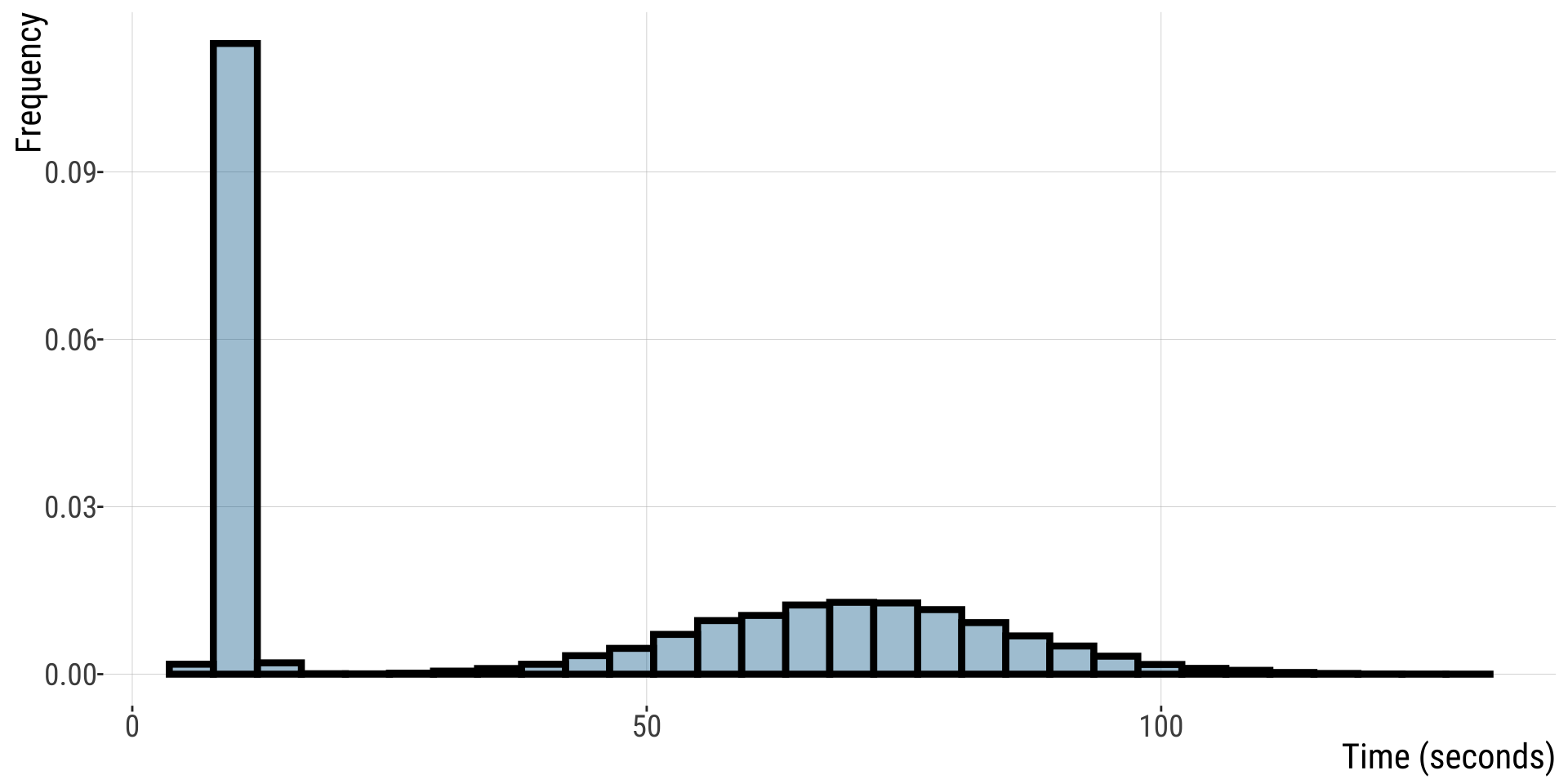
QQ-plots and the eye test (3/)
In R We can make a qq-plot with the geom_qq() function and add a line with geom_qq_line(), here we map our quantity of interest onto the attribute, sample.
For this non-normal distribution, values fall far away from the QQ line.
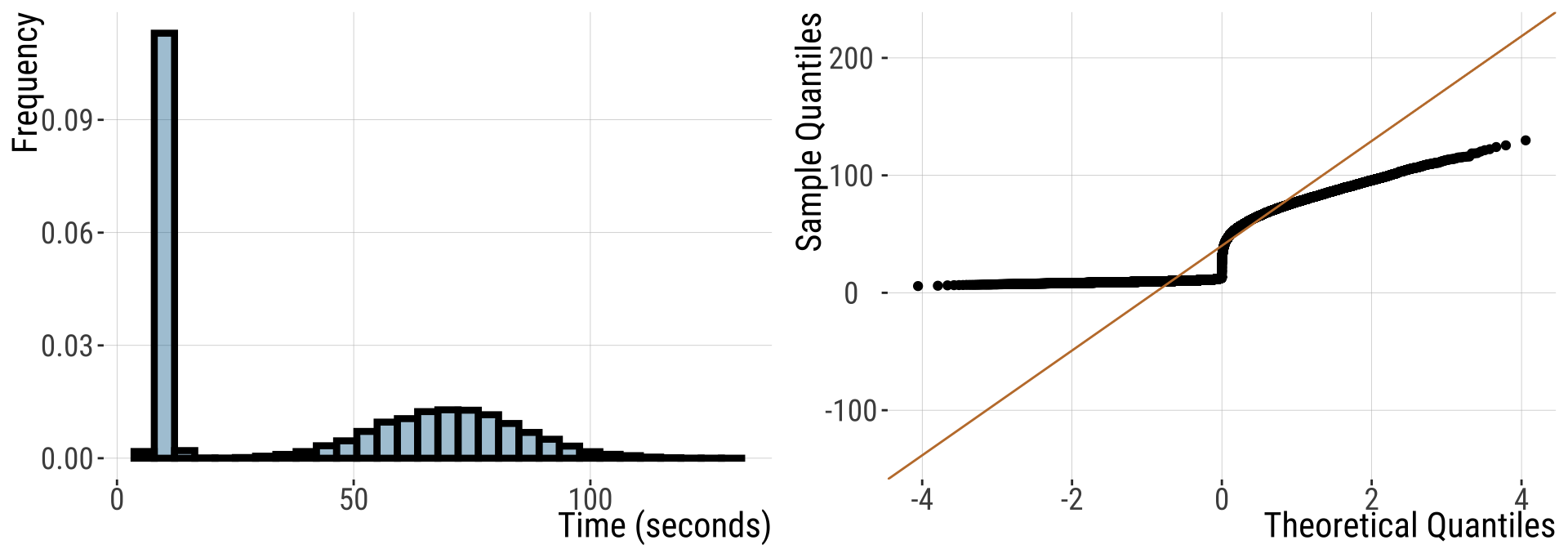
- The red line shows where values should fall if \(y\) is normally distributed.
QQ-plots and the eye test (4/)
For this normally distributed data, values fall nicely on the QQ line
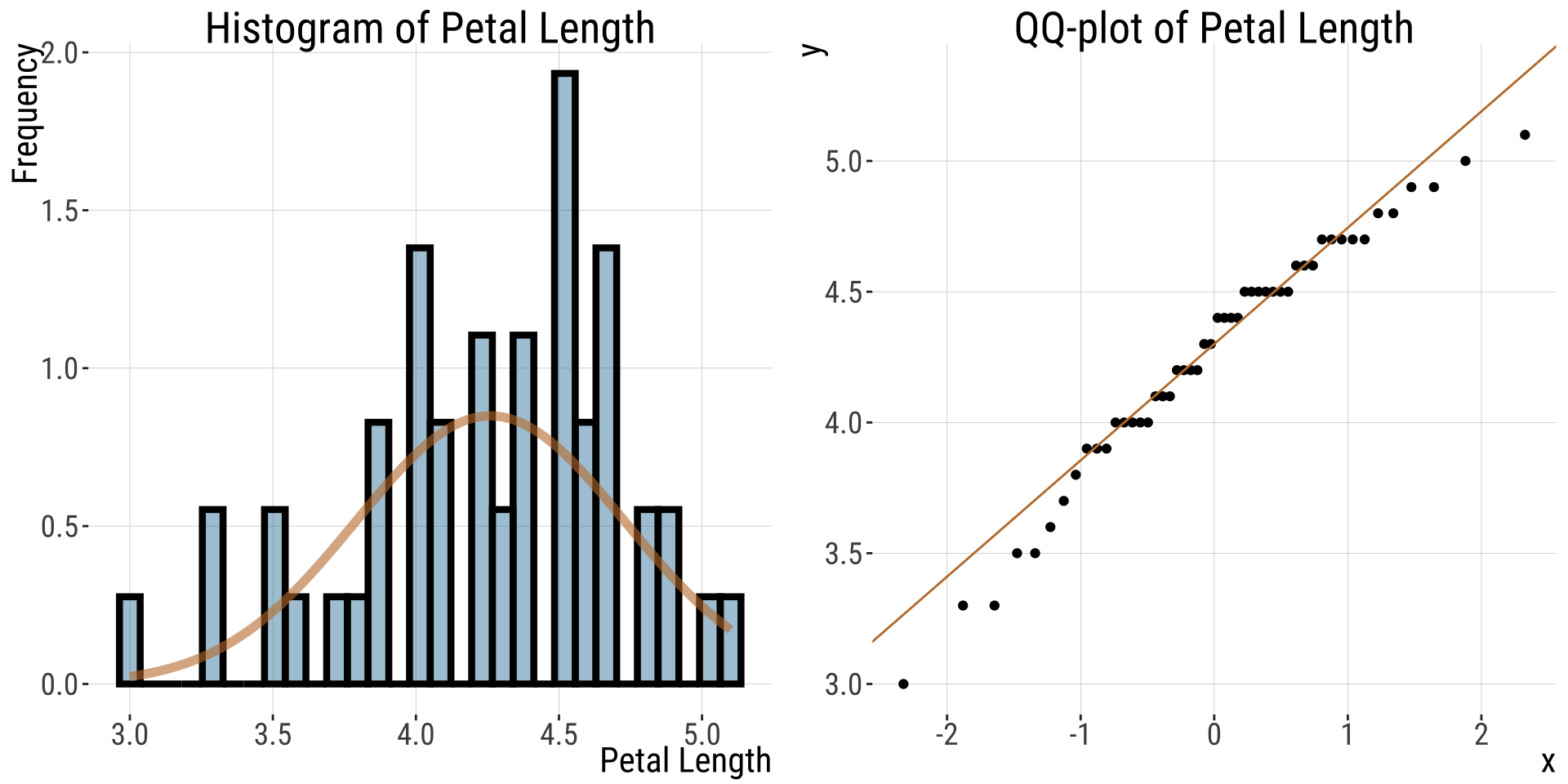
- The red line shows where values should fall if \(y\) is normally distributed.
QQ-plots and the eye test (5/)
- Points seem to be pretty close to the predicted line, but both the small and large values are a bit smaller than we expect.
- Is this a big deal? Is this deviation surprising? To find out we need to get a sense of the variability we expect from a normal distribution.
What normal distributions look like
- I am always surprised about how easily I can convince myself that a sample does not come from a normal distribution.
- To give you a sense: run this about ten times for five quite different sample sizes to get a sense for the variability in how normal a sample from the normal distribution looks.
- This basically takes your sample size,
n, and simulates random data from the standard normal by running this R codetibble(x = rnorm(n = n, mean = 0, sd = 1)), and then plotting the output:
Violation of normality assumption (1/)
- The Normal distribution is very common and the CLT is very useful
- There are a bunch of statistical approaches made for data with some form of normality assumption.
- But sometimes data are too far from normal to be modeled as if they are normal
Violation of normality assumption (2/)
- Or, details of a statistical distribution lead to breaking other assumptions of statistical tests. When this happens, we have a few options:
- We can transform the data to meet our assumptions
- Use non-parametric tests (don’t make assumptions about underlying distributions)
- We can permute and bootstrap! (sampling/simulation approaches)
- We can use/develop tools to model the data as they are actually distributed
Rules for legit transformations (1/)
- There is nothing “natural” about linear scale, so there is nothing wrong about transforming data to a different scale.
- We should estimate & test hypotheses on a meaningful scale.
- An appropriate transformation will often result in normal-ish distributed data.
- Let biology guide you. Often you can think through what transformation is appropriate by thinking about a mathematical model describing your data. E.g., if values naturally grow exponentially, you should probably log-transform your data.
Rules for legit transformations (2/)
Apply the same transformation to each individual.
Transformed values must have one-to-one correspondence to original values - don’t square if some values are >0 and some are <0.
Transformed values must have a monotonic relationship with the original values - e.g., larger values stay larger, so be careful with trigonometric transformations.
Conduct your statistical tests AFTER you settle on the appropriate transformation.
Do not bias your results by losing data points when transforming the data.
Common transformations
- There are numerous common transformations that will make data normal, depending on their initial shape.
| Name | Formula | What type of data? |
|---|---|---|
| Log | \(Y'=\log_x(Y + \epsilon)\) | Right skewed |
| Square-root | \(Y'=\sqrt{Y+1/2}\) | Right skewed |
| Reciprocal | \(Y'=1/Y\) | Right skewed |
| Square | \(Y'=Y^2\) | Left skewed |
| Exponential | \(\displaystyle Y'=e^Y\) | Left skewed |
- We saw an example in lab 10
The log transformation (1/)
- We have seen that the normal distribution arises when we add up a bunch of things.
- If we multiply a bunch of things, we get an exponential distribution.
- Because adding logs is like multiplying untransformed data, a log transform makes exponential data look normal!
- Be careful when log-transforming!! All data with a value of zero or less will disappear. For this reason, we often use a
log1ptransform, which adds one to each number before logging them.
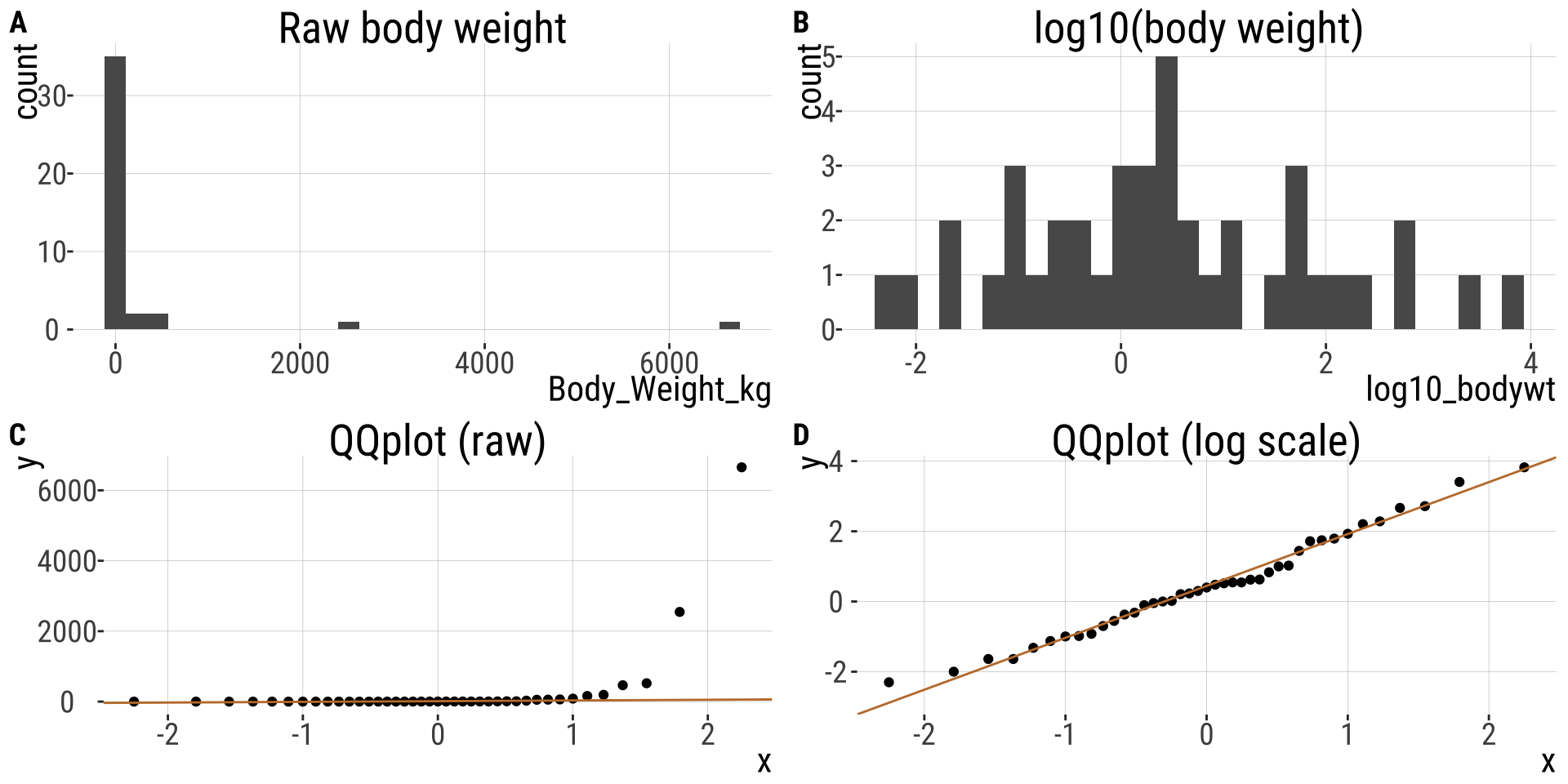
The log transformation (2/)
- Body weight in mammals
Practice Problems
Problem 1: Notation
What is the correct representation for the 3% critical t-value for a sample with 14 degrees of freedom?
Problem 2: Coconut attack
A four-year review at the Provincial Hospital in Alotau, Papua New Guinea (Barss 1984), found that about 1/2 of their hospital admissions were injuries due to falling coconuts. If coconuts weigh on average 3.2kg and the upper bound of the 95% confidence interval is 3.5kg what is the lower bound of this confidence interval? Assume a normal distribution of coconut weights.
Problem 3: Using the Student’s t table
Using your table of critical t-values, what value of t corresponds to the location with 95% of the area under the curve to the left and 5% to the right when there are 18 degrees of freedom?
1.330
1.734
2.101
2.214
Problem 4: Using the Student’s t table
Using your table of critical t-values, what values of t correspond to the ones that bound a central region containing 95% of the distribution when there are 18 degrees of freedom?
−2.101 to 2.101
−1.734 to 1.734
−1.051 to 1.051
−0.867 to 0.867
Problem 5:
If the sample mean matches the hypothesized population mean, then the t-statistic and P-value of the test would be which of the following?
0, 1
1, 0
1, 1
Cannot be determined, depends on the sample size.
Problem 6:
How many standard errors wide is a 95% confidence interval for a population mean, based on a sample of size 10?
Problem 7:
If we have a 95% confidence interval of 20.68 < μ < 21.32 based on a sample of 18 values, what is the standard deviation of the sample?
Problem 8:
Consider a situation in which Michael collects 12 frogs from a population that he thinks (based on published reports) has an average of 21 spots. His sample has a mean of 23 with a standard deviation of 3.1, however. Conduct a one-sample t-test. State the hypotheses, calculate df, t, and find a range for the P-value. What can you conclude?
Problem 9: Swimming in syrup
It is unknown whether the increase in the friction of the body moving through the syrup (slowing the swimmer down) is compensated by the increased power of each stroke. Experiment: researchers filled one pool with water mixed with syrup and another pool with normal water. They had 18 swimmers swim laps in both pools in random order. Data: the relative speed of each swimmer in syrup (speed in the syrup pool divided by his or her speed in the water pool). If the syrup has no effect on swimming speed, then relative swim speed should have a mean of 1. I calculated the mean and sd for you: \(\bar{X}=1.011667\), \(s=0.04232229\)
- Test the hypothesis that relative swim speed in syrup has a mean of 1.
- How uncertain are we about true relative swimming speed in syrup? Use the 99% confidence interval to find out.
1. Quantify the effect size using Cohen’s d.[ignore this one]
Problem 10: Has Climate Change Moved Species Uphill? (1/)
Chen et al. (2011) wanted to test the idea that organisms move to higher elevation as the climate warms. To test this, they collected data from 31 species:
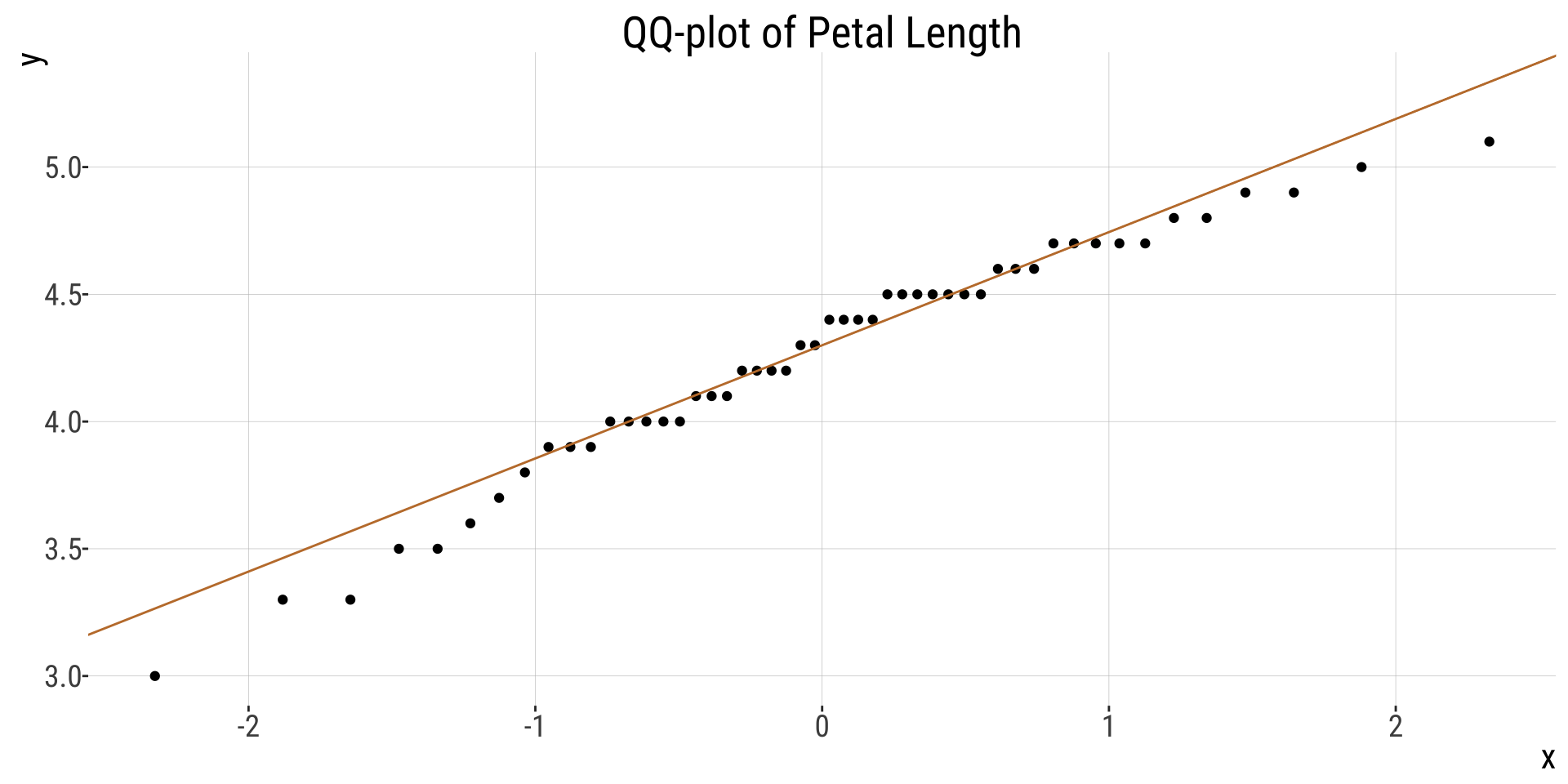
Has Climate Change Moved Species Uphill? (2/)
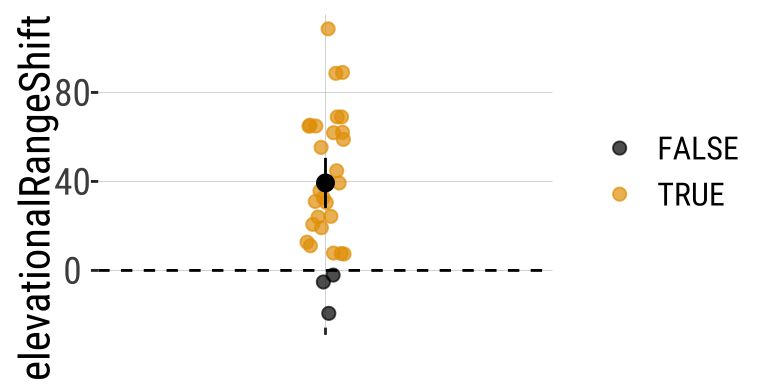
Change in the elevation of 31 species. Data from @Chen2011.
Has Climate Change Moved Species Uphill? (3/)
Estimation
The first step is to summarize the data
| n | this_mean | this_sd | this_sem |
|---|---|---|---|
| 31 | 39.32903226 | 30.66311784 | 5.507258541 |
Ranges have shifted about 39.3 meters upwards - > 1 SD change in elevation across species.
Has Climate Change Moved Species Uphill? (4/)
Evaluating assumptions
- Are data biased? I hope not, but it would depend on aspects of study design etc. For example, we might want to know if species had as much area to increase in elevation as to decrease etc…. How were species picked….
- Are data independent? Check out the data above. My sense is that they aren’t all independent. So much data is from the UK. What if there is something specific about low elevation regions in the UK? Anyways, I wouldn’t call this a reason to stop the analysis, but it is a good thing to consider.
- Is the mean a meaningful summary of the data? My sense is yes, but look for yourself!
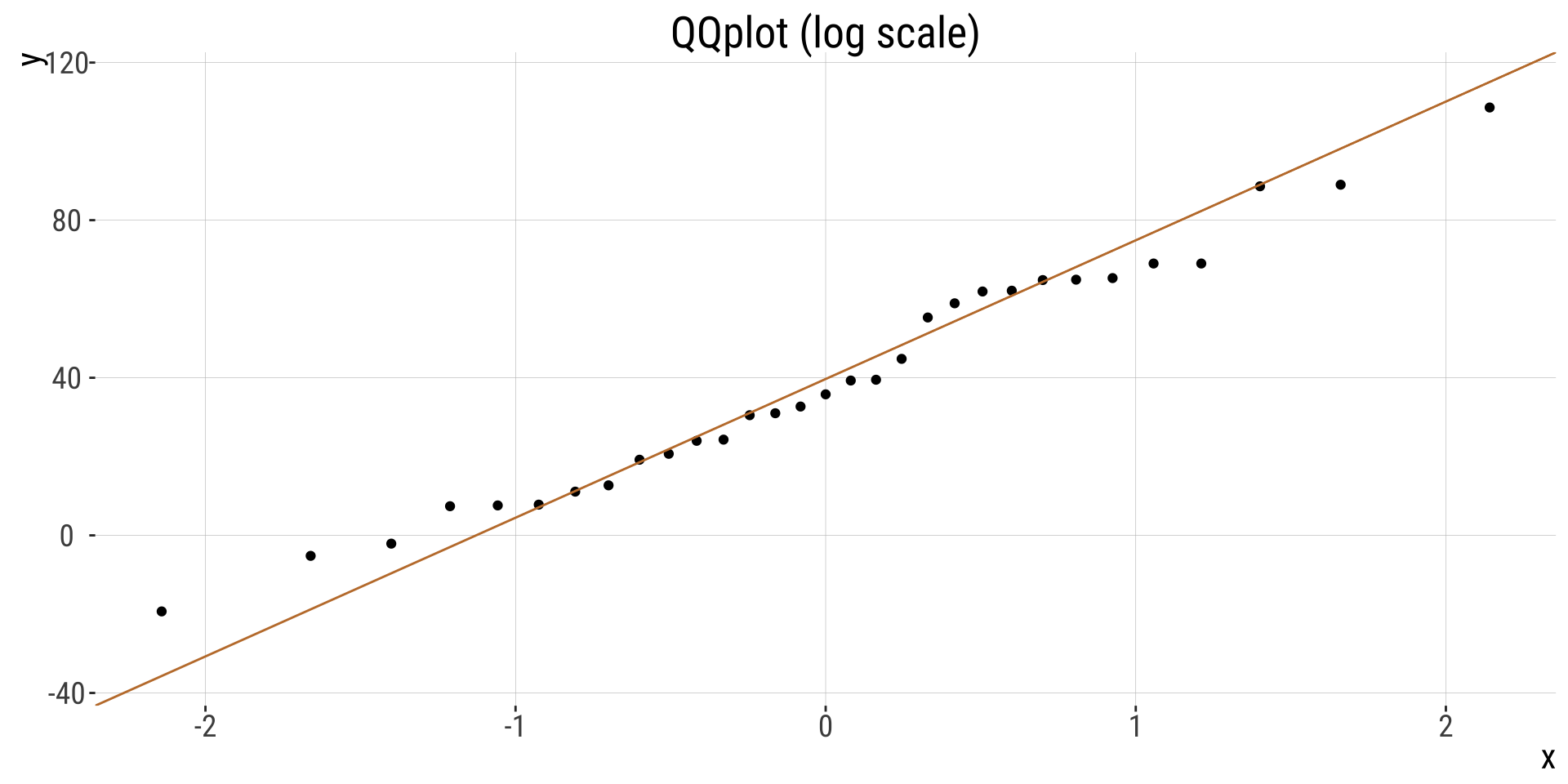
- Are samples (or more particularly, the sampling distribution) normal? My sense is yes, but look for yourself! My sense is yes, but look for yourself!
- How? QQ-plot, histogram, density plot…
QQplot
Hypothesis Testing
Let’s lay out the null and alternative hypotheses:
\(H_{0}:\) On average organisms have not increased or decreased their elevation.
\(H_{A}:\) On average organisms have increased or decreased their elevation.
First let’s calculate \(t\) and then use pt() to find the probability and multiply by two.
Hypothesis Testing
| df | t | p_val |
|---|---|---|
| 30 | 7.141308505 | 6.06e-08 |
- A really small p-value, meaning that the null hypothesis would rarely generate such extreme data.
- Since p < traditional \(\alpha\) threshold we reject the \(H_{0}\) and conclude that ranges have shifted upward.
- Note this doesn’t mean the null is wrong, it just means that we’re proceeding as if it is.
For future refence
Statistics for Biologists - Nature collection of articles highlighting important statistical issues that biologists should be aware of and provides practical advice to help them improve the rigor of their work.nature.com/collections/qghhqm
G*power: a tool to compute statistical power analyses for many different t tests, F tests, χ2 tests, z tests and some exact tests. G*Power can also be used to compute effect sizes and to display graphically the results of power analyses. www.psychologie.hhu.de/arbeitsgruppen/allgemeine-psychologie-und-arbeitspsychologie/gpower
The
pwrpackage in R is a powerful tool for conducting power analysis. Power analysis is essential in determining the sample size needed to detect an effect of a given size with a certain level of confidence. It is widely used in experimental design and statistical hypothesis testing. data-wise.github.io/doe/appendix/r-packages/pwr.htmlOur course website! https://bbitarello.github.io/b215f2025/